-
一张图即可生成电影级数字人视频:阿里云通义万相 Wan2.2-S2V 视频生成模型宣布开源
Wan2.2-S2V 可驱动真人、卡通、动物、数字人等类型图片,并支持肖像、半身以及全身等任意画幅,上传一段音频后,模型就能让图片中的主体形象完成说话、唱歌和表... -
支持部分独立使用:阿里通义实验室推出开源智能体开发框架 AgentScope 1.0
该框架包含三层技术架构:核心框架负责智能体构建与应用编排,Runtime 提供安全运行环境,Studio 提供可视化监控工具。 -
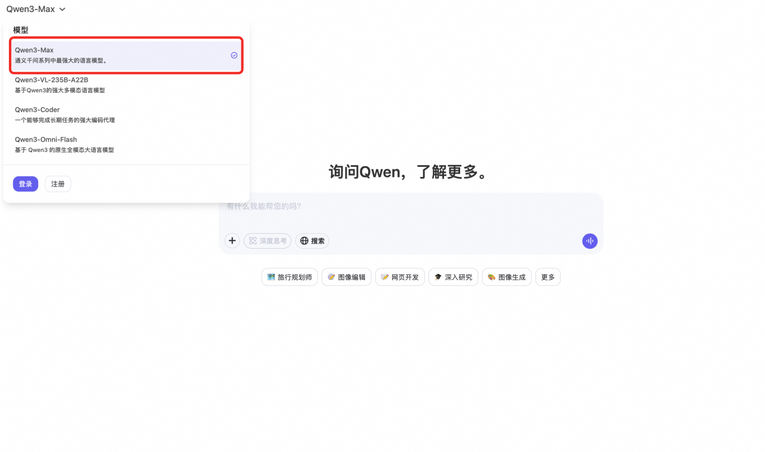
通义千问系列最强大的语言模型:Qwen3-Max-Preview 上线
阿里通义千问今日在官网和OpenRouter上线了最新的Qwen-3-Max-Preview模型。根据官网描述,该模型是通义千问系列中最强大的语言模型。 -
参数量 1T,阿里官方介绍“通义最强语言模型”Qwen3-Max-Preview
昨晚,阿里悄悄在通义千问官网、OpenRouter 上线了 Qwen3-Max-Preview 模型,并称其为通义千问系列中最强大的语言模型。随后,通义大模型通... -
阿里云发布通义 Qwen3-Next 基础模型架构并开源 80B-A3B 系列:改进混合注意力机制、高稀疏度 MoE 结构
阿里云通义团队发布Qwen3-Next基础模型架构,开源80B-A3B系列模型,改进混合注意力机制与高稀疏度MoE结构,训练成本仅为Qwen3-32B的十分之一... -
阿里云发布通义 Qwen3-Next 基础模型架构并开源 80B-A3B 系列:改进混合注意力机制、高稀疏度 MoE 结构
阿里云通义团队发布Qwen3-Next基础模型架构,开源80B-A3B系列模型,改进混合注意力机制与高稀疏度MoE结构,训练成本仅为Qwen3-32B的十分之一... -
阿里通义深夜炸场:全球首个端到端全模态 AI 模型 Qwen3-Omni 发布开源,文本、图像、音视频全统一
Qwen3-Omni 是业界首个原生端到端全模态 AI 模型,能够处理文本、图像、音频和视频多种类型的输入,并可通过文本与自然语音实时流式输出结果。 -
阿里云栖大会一口气发布千问 3-VL、万相 2.5 等六大模型 + 通义百聆新品牌,覆盖文本、视觉、语音、视频、代码、图像全场景
阿里云栖大会发布六大AI模型及通义百聆品牌,覆盖文本、视觉、语音、视频、代码、图像全场景。其中Qwen3-VL支持2小时视频精确定位,Qwen-Image实现“... -
参数超万亿:阿里发布通义千问最强 AI 大模型 Qwen3-Max 正式版,性能全面领先
继 Qwen3-2507 系列发布之后,阿里云今天宣布推出 Qwen3-Max —— 通义团队迄今为止规模最大、能力最强的语言模型。......">科沃斯与阿里云达成全栈 AI 合作,扫地机器人接入通义千问
据阿里云官方消息,近日,科沃斯与阿里云达成全栈 AI 战略合作,双方将面向具身智能在 AI 算力、端侧模型部署、VLM 等领域共同研发,科沃斯还将基于通义千问打...