使用场景使用InternVL2_5-1B模型进行图像和文本的联合理解和推理任务。在多图像理解任务中,利用InternVL2_5-1B模型分析和比较不同图像内容。...
AI模型,开发平台,多模态,大型语言模型,图像识别,文本理解,机器学习,普通产品,开源,
0
使用场景设计师使用AI Vector Creator快速生成网站插图。营销团队利用该工具为社交媒体帖子创建引人注目的视觉内容。教育机构制作教学材料时,使用AI ...
AI设计工具,图片生成,矢量图像,AI设计,图形编辑,在线工具,设计自动化,普通产品
0
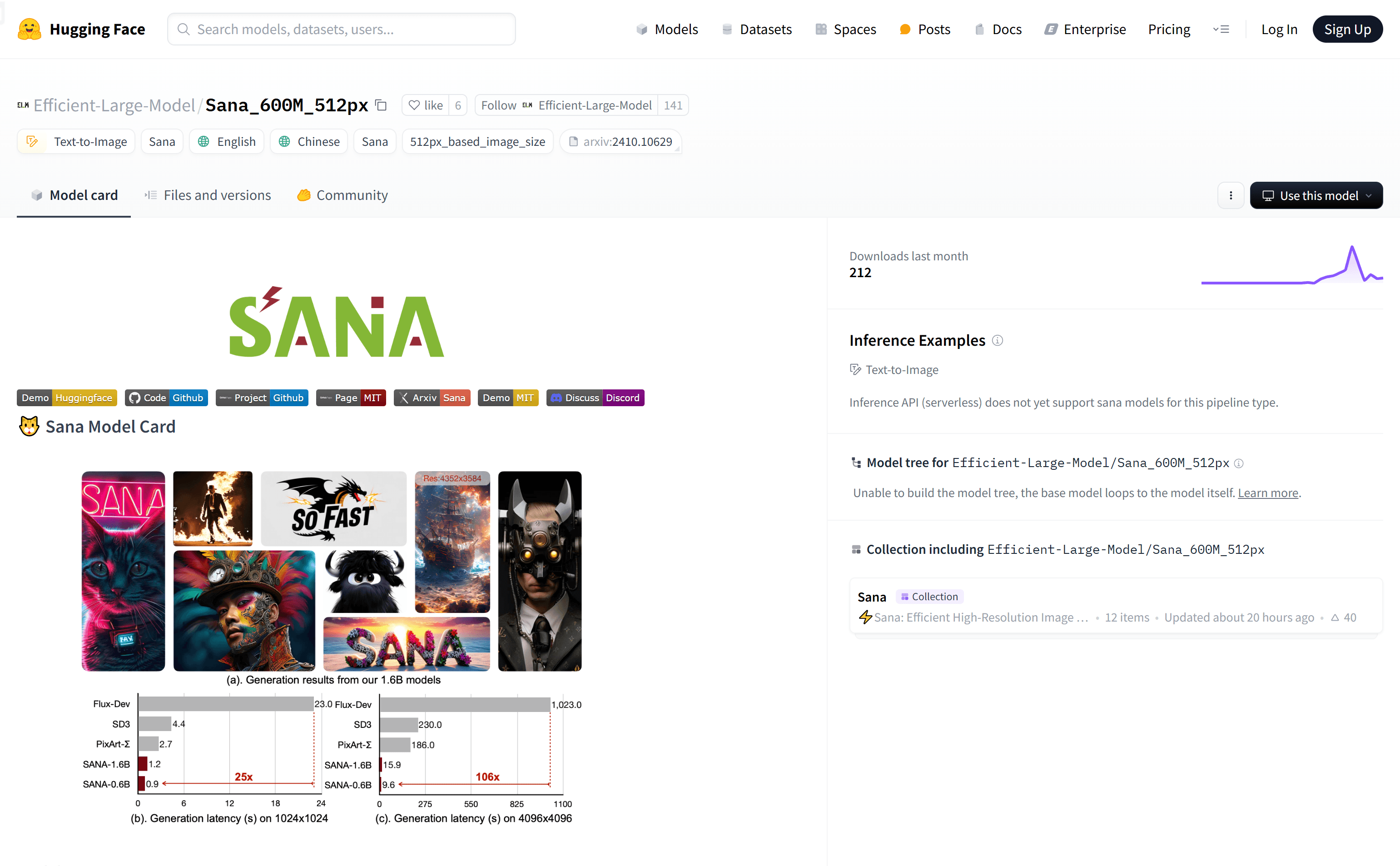
使用场景案例一:艺术家使用Sana根据文本描述生成具有特定风格的艺术作品。案例二:设计师利用Sana快速生成产品原型图,加速设计流程。案例三:教育工作者在课堂上...
图片生成,AI模型,文本到图像,高分辨率,线性扩散变换器,NVIDIA,图像生成,普通产品,开源,
0
使用场景使用InternViT-300M-448px-V2_5进行图像分类任务,以识别和分类不同的图像内容。在多语言OCR数据上应用该模型,以提高文本识别的准确...
AI模型,图片编辑,视觉特征提取,多模态学习,增量学习,大规模数据集,图像分类,语义分割,普通产品,开源,
0
使用场景案例一:使用InternViT-6B-448px-V2_5进行图像分类,识别图像中的主要对象。案例二:在多语言文档处理中,利用模型进行OCR数据的识别和...
AI模型,图片编辑,视觉模型,特征提取,多模态,OCR,图像识别,普通产品,开源,
0
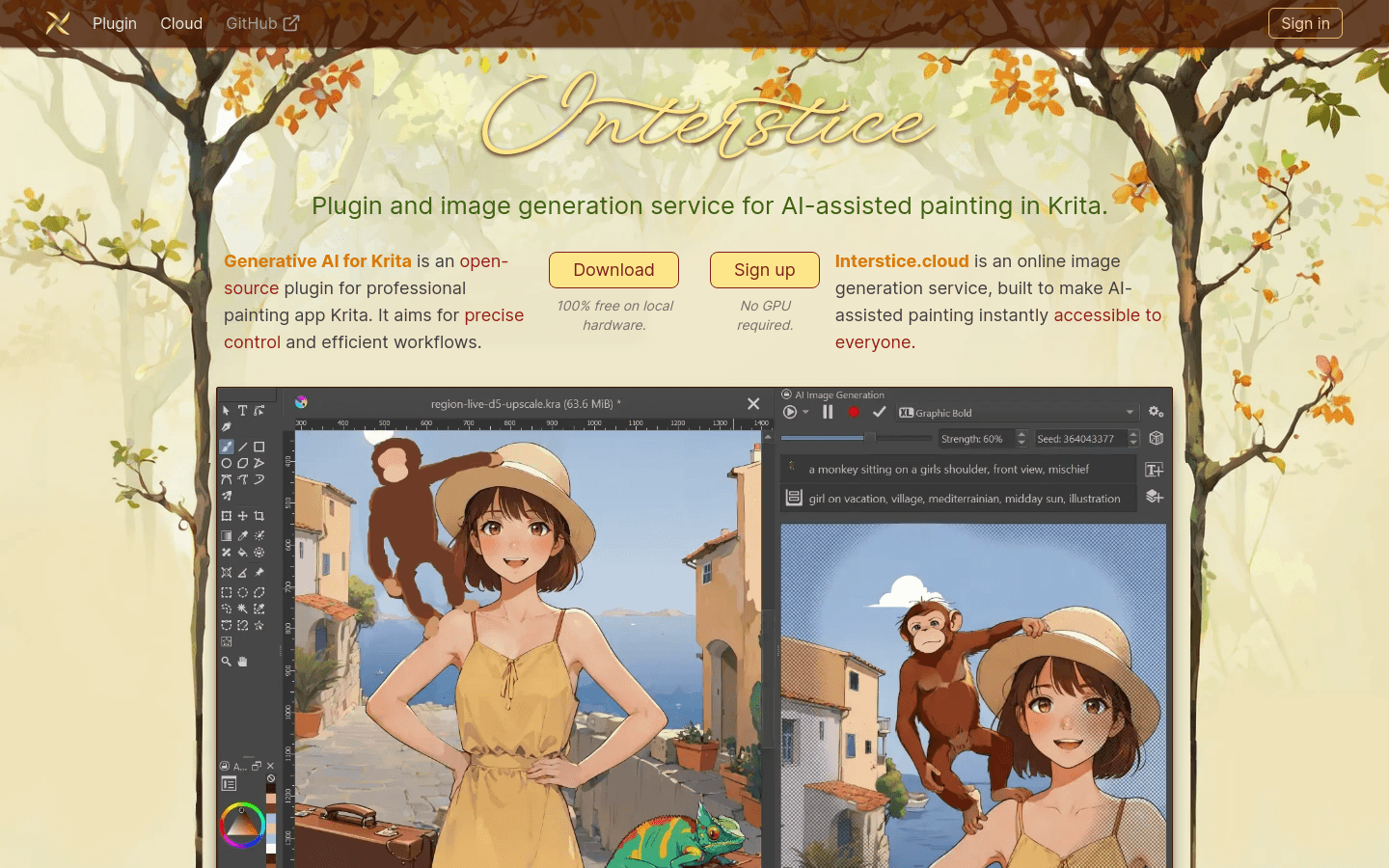
使用场景案例一:专业画家使用Interstice插件在Krita中进行精确的局部编辑和创作。案例二:设计师通过Interstice.cloud在线服务快速生成设...
AI设计工具,图片编辑,AI辅助绘画,Krita插件,图像生成,在线服务,设计工具,普通产品
0
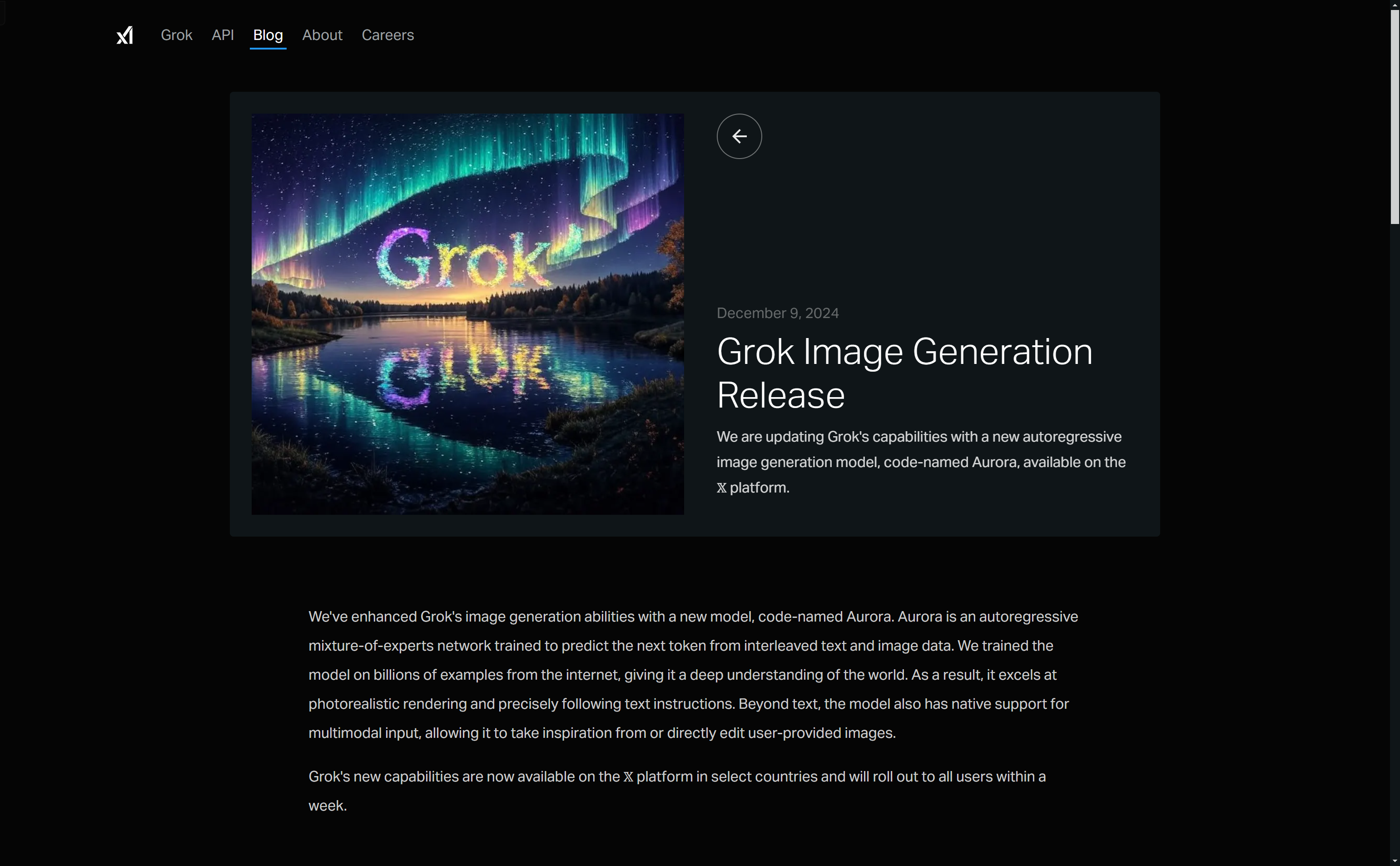
使用场景生成抽象风格的洛克希德SR-71黑鸟飞机图像。将Optimus角色融入圣诞节场景并穿上圣诞服装。为'GROK'品牌设计一个金色太阳镜风格的创意标志。产品...
图片生成,AI模型,图像生成,AI,自回归模型,多模态输入,文本到图像,普通产品
0
使用场景- 使用InternVL2_5-8B进行图像描述和图像问答。- 利用模型进行多语言的图像标注和分类。- 将模型应用于视频内容的理解和分析。产品特色- 动...
AI模型,多模态,多模态,大型语言模型,图像-文本-文本,Transformers,TensorBoard,Safetensors,多语言,普通产品,开源,
0
使用场景案例一:研究人员使用Sana模型生成特定风格的艺术作品,用于分析和比较不同图像生成技术的效果。案例二:设计师利用Sana模型快速生成设计草图,提高工作效...
图片生成,AI模型,文本到图像,高分辨率,图像合成,NVIDIA,开源,普通产品,开源,
0
使用场景用于图像和文本的联合理解任务,如图像描述生成。在视频内容分析中,用于理解视频内容并生成视频摘要。作为聊天机器人的底层技术,提供图像和文本交互的能力。产品...
AI模型,AI信息平台,多模态,大型语言模型,图像识别,视频分析,自然语言处理,普通产品,开源,
0
使用场景使用InternVL2_5-78B进行图像描述生成,将图像内容转化为文字描述。在多图像理解任务中,利用InternVL2_5-78B分析和比较不同图像之...
AI模型,多模态模型,多模态,大型语言模型,视觉感知,图像-文本转换,机器学习,普通产品,开源,
0
使用场景案例一:电商网站使用InternVL为商品图片提供自动描述,提升用户体验。案例二:科研机构利用InternVL分析实验图像,加速研究进程。案例三:安全监...
图片生成,AI信息平台,AI,图像识别,深度学习,视觉语言模型,普通产品
0
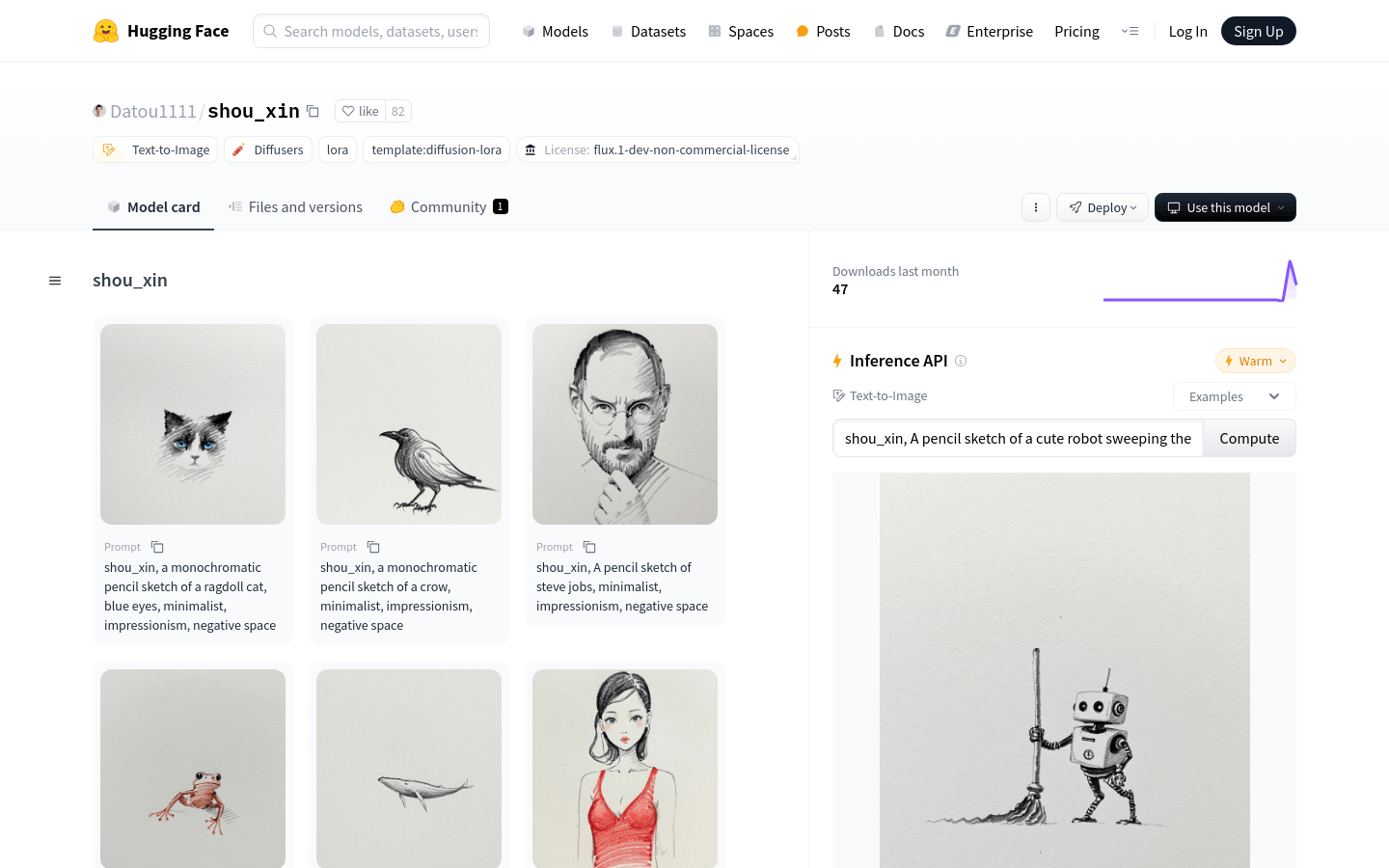
使用场景生成一只蓝眼睛的布偶猫的铅笔素描创作一幅史蒂夫·乔布斯的极简主义铅笔素描绘制一只穿着红色连衣裙的女性的写实风格铅笔素描产品特色根据文本提示生成手訫风格的...
图片生成,AI设计工具,文本到图像,铅笔素描,艺术风格,图像生成,diffusers,lora,普通产品,开源,
0
使用场景研究人员使用Florence-VL进行图像和文本的联合表示学习,以提高模型在视觉问答任务中的表现。开发者利用Florence-VL提供的预训练模型,快速...
AI模型,图片生成,视觉语言模型,多模态学习,深度学习,自然语言处理,图像识别,普通产品,开源,
0
使用场景• 使用Sana模型根据文本提示生成一幅穿着T恤吹萨克斯的老虎图像。• 根据混合语言提示生成一幅猫戴着墨镜在彩虹上飞翔,手中拿着玫瑰的图像。• 生成一幅...
图片生成,AI模型,文本到图像,高分辨率,多语言,NVIDIA,图像合成,普通产品,开源,
0
使用场景- 利用Qwen2-VL-2B进行文档的视觉问答,提高信息检索的效率。- 将Qwen2-VL-2B集成到机器人中,使其能够根据视觉环境和指令执行任务。-...
AI模型,视频生成,视觉语言模型,多模态,图像理解,视频理解,文本生成,多语言支持,普通产品,开源,
0
使用场景老照片修复:将年代久远的黑白照片通过Color-diffusion进行上色,恢复照片原有的色彩。艺术创作:艺术家可以使用Color-diffusion为...
图片编辑,AI设计工具,图像着色,扩散模型,LAB颜色空间,UNet,开源项目,普通产品,开源,
0
使用场景设计师使用AWPortraitCN生成时尚杂志封面人物肖像。摄影师利用模型创建摄影棚风格的人物肖像。艺术家用于创作具有中国特色的数字艺术作品。产品特色-...
图片生成,AI模型,文本到图像,肖像生成,FLUX.1-dev,AWPortraitSR,皮肤质感,在线推理,普通产品,开源,
0
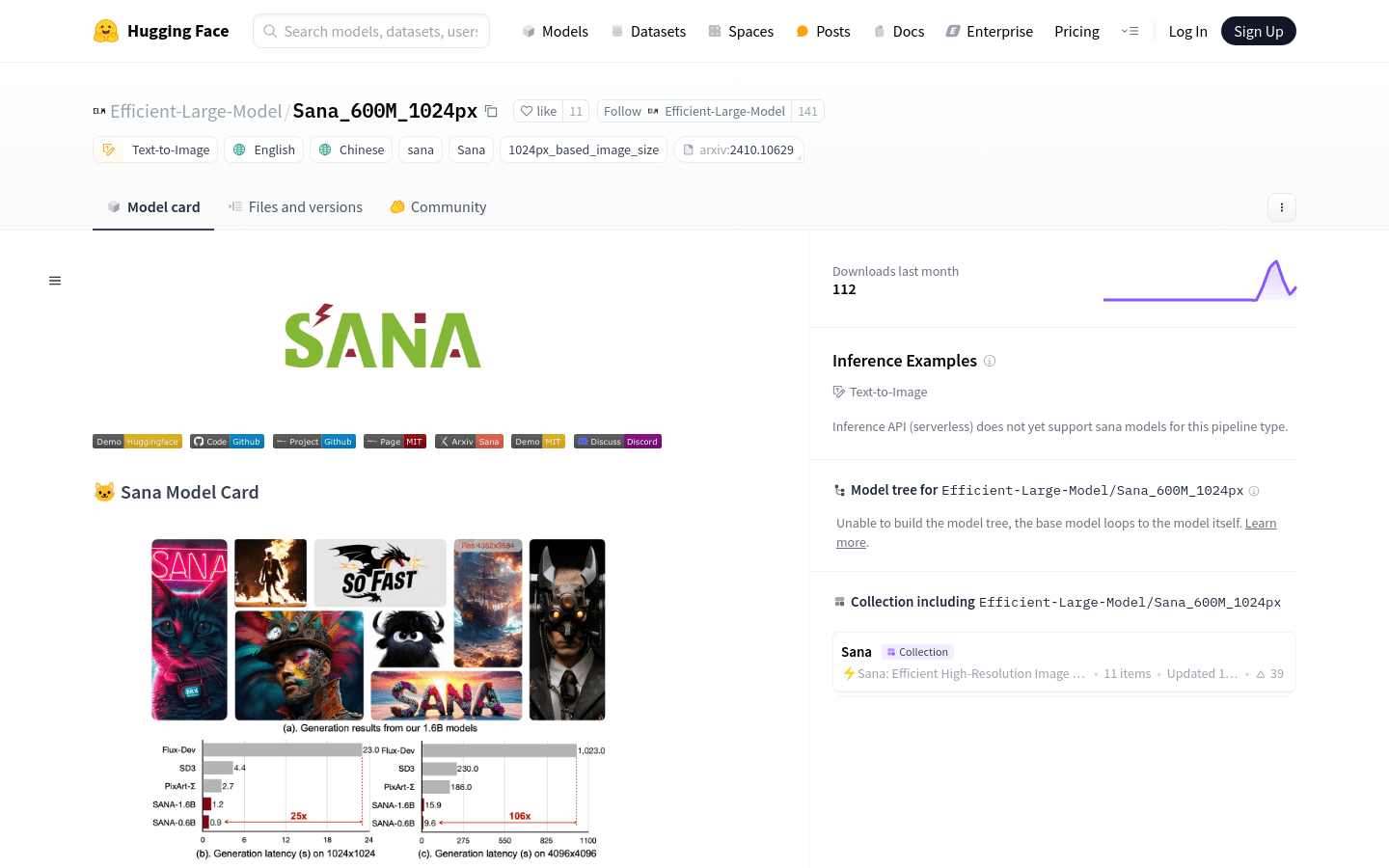
使用场景• 使用Sana模型根据文本提示生成具有传统中国风格的长城图像。• 利用Sana模型创作一幅穿着T恤吹萨克斯风的老虎图像。• 通过Sana模型生成一幅狮...
图片生成,AI设计工具,文本到图像,高分辨率,多语言,NVIDIA,线性扩散变换器,普通产品,开源,
0
使用场景ColPali在视觉文档检索方面的进展RoboFlow的微调技术实时目标跟踪技术产品特色• 可扩展性能:提供多种模型尺寸和分辨率,以适应不同任务的性能需...
AI模型,图片生成,视觉语言模型,AI,机器学习,深度学习,图像识别,自然语言处理,普通产品
0