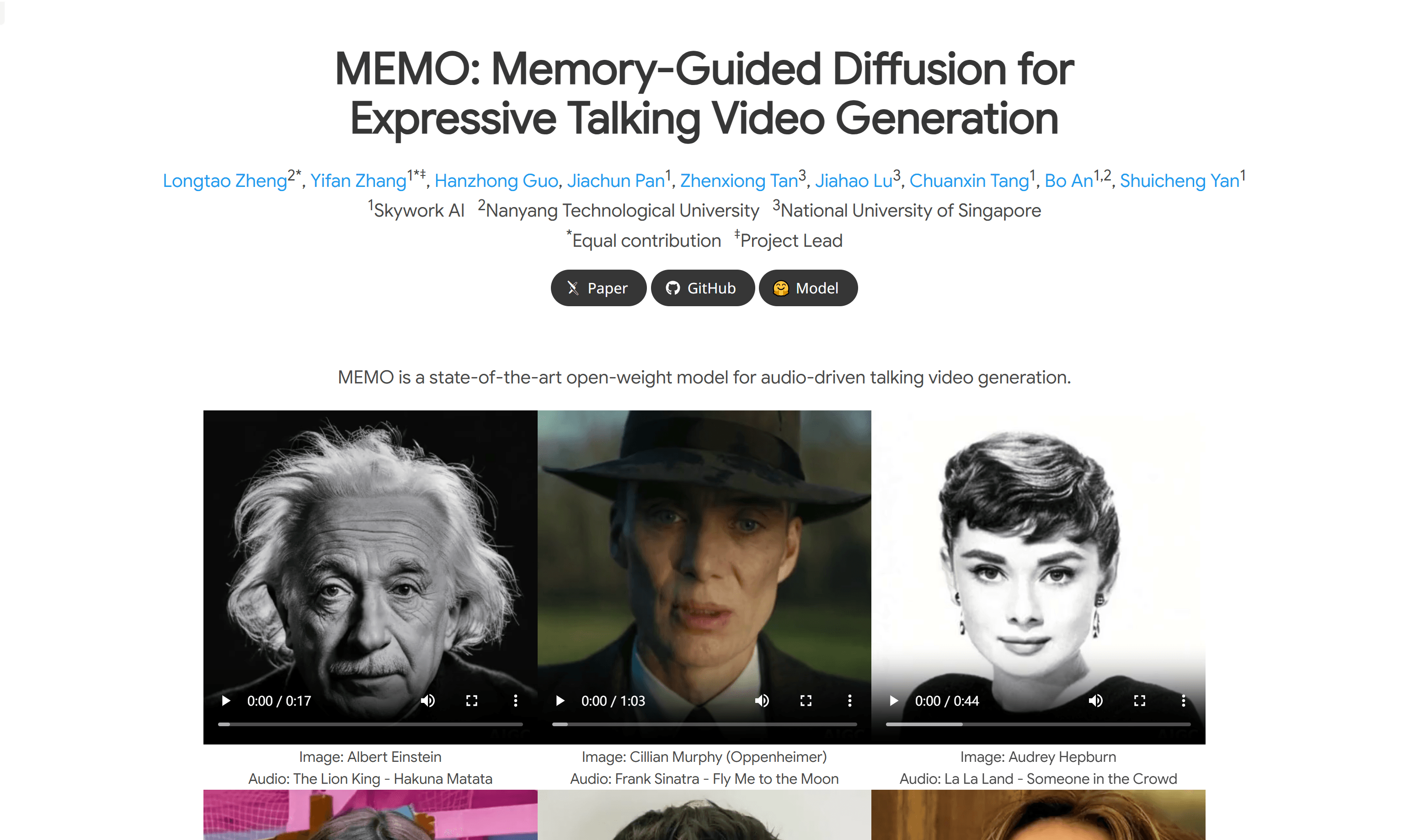
使用场景使用爱因斯坦的肖像和《狮子王》的音频生成说话视频。将奥黛丽·赫本的肖像与《爱乐之城》的音频结合起来,生成富有表情的视频。使用Jang Won-young...
视频生成,AI模型,视频生成,音频驱动,面部表情,身份一致性,情感检测,普通产品,开源,
08月02日
0
使用场景- 利用Qwen2-VL-2B进行文档的视觉问答,提高信息检索的效率。- 将Qwen2-VL-2B集成到机器人中,使其能够根据视觉环境和指令执行任务。-...
AI模型,视频生成,视觉语言模型,多模态,图像理解,视频理解,文本生成,多语言支持,普通产品,开源,
08月02日
0
使用场景案例一:使用Qwen2-VL-7B进行视频内容的自动摘要和问题回答。案例二:集成Qwen2-VL-7B到移动应用中,实现基于图像的搜索和推荐。案例三:利...
AI模型,视频生成,视觉语言模型,多模态,文本生成,视频理解,多语言支持,普通产品,开源,
08月02日
0
使用场景使用Qwen2-VL-72B进行数学问题的图像识别和解答在长视频中进行内容创作和问答系统的开发集成到机器人中,实现基于视觉指令的自动导航和操作产品特色支...
AI模型,视频生成,视觉理解,视频问答,自动操作,多语言支持,多模态处理,普通产品,开源,
08月02日
0
使用场景• 3D艺术家使用TRELLIS从文本提示生成具有复杂几何和纹理的3D模型。• 游戏开发者利用TRELLIS创建多样化的游戏环境和角色模型。• 电影制作...
3D建模,AI模型,3D生成,机器学习,视觉特征,模型训练,结构化潜在表示,普通产品,开源,
08月02日
0
使用场景• 使用Sana模型根据文本提示生成一幅穿着T恤吹萨克斯的老虎图像。• 根据混合语言提示生成一幅猫戴着墨镜在彩虹上飞翔,手中拿着玫瑰的图像。• 生成一幅...
图片生成,AI模型,文本到图像,高分辨率,多语言,NVIDIA,图像合成,普通产品,开源,
08月02日
0
使用场景研究人员使用Florence-VL进行图像和文本的联合表示学习,以提高模型在视觉问答任务中的表现。开发者利用Florence-VL提供的预训练模型,快速...
AI模型,图片生成,视觉语言模型,多模态学习,深度学习,自然语言处理,图像识别,普通产品,开源,
08月02日
0
使用场景• 作为聊天机器人,提供客户服务支持。• 在编程辅助中,帮助开发者理解和生成代码。• 用于教育领域,提供多语言教学辅助。产品特色• 支持多语言对话:包括...
聊天机器人,AI模型,多语言,预训练模型,对话系统,自然语言处理,普通产品,开源,
08月02日
0
使用场景用于训练一个能够理解多种语言的聊天机器人。作为开发一个支持多国语言文本翻译应用的数据基础。用于分析不同语言中的情感倾向,以优化产品的本地化策略。产品特色...
AI模型,开发与工具,多语言,预训练,NLP,Hugging Face,数据集,普通产品,开源,
08月02日
0
使用场景在金融领域,Deepthought-8B可以用于风险评估,通过透明推理帮助分析师理解模型决策。在医疗领域,模型可以辅助医生进行诊断,提供结构化的推理过程...
研究工具,AI模型,文本生成,推理,对话,英语,普通产品,开源,
08月02日
0