在人工智能的不断发展中,扩散模型在推理能力上逐渐崭露头角,现如今,它们不再是自回归模型的 “跟随者”。近日,来自加州大学洛杉矶分校(UCLA)和 Meta 的研...
强化学习,应用
07月30日
0
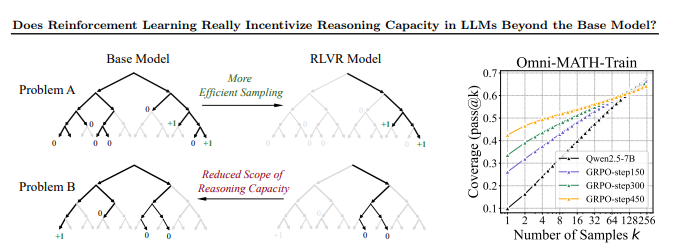
【研究颠覆】清华大学与上海交通大学联合发表的最新论文,对业界普遍认为"纯强化学习(RL)能提升大模型推理能力"的观点提出了挑战性反驳。研究发现,引入强化学习的模...
清华,大模型,强化学习
07月30日
0
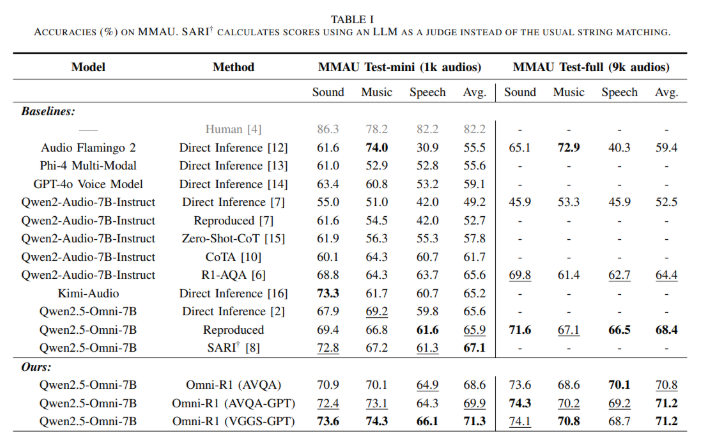
最近,一项来自 MIT CSAIL、哥廷根大学、IBM 研究所等机构的研究团队提出了一个名为 Omni-R1的全新音频问答模型。该模型在 Qwen2.5-Omn...
音频,问答,文本,强化学习,数据
07月30日
0
近期,谷歌 DeepMind 团队与约翰・开普勒林茨大学 LIT AI 实验室合作,开展了一项关于人工智能语言模型的新研究。他们采用了强化学习微调(RLFT)技...
谷歌,DeepMind,强化学习,AI,决策
07月30日
0
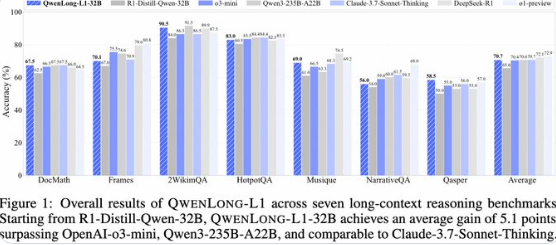
阿里巴巴今日正式发布QwenLong-L1-32B,这是一款专为长上下文推理设计的大型语言模型,标志着AI长文本处理能力的重大突破。该模型在性能表现上超越了o3...
阿里,性能,Qwen,强化学习,文本,Claude
07月30日
0
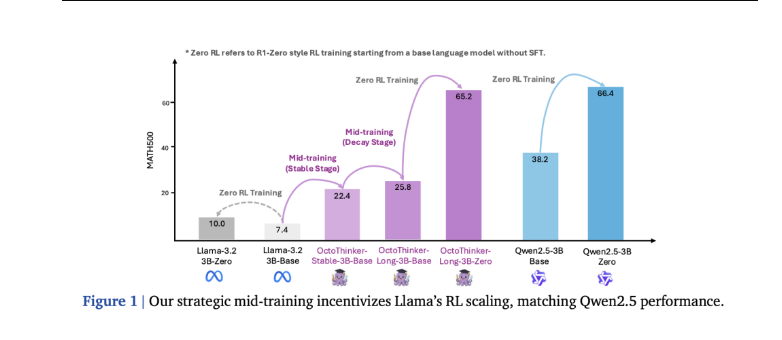
大型语言模型(LLM)通过结合任务提示和大规模强化学习(RL)在复杂推理任务中取得了显著进展,如 Deepseek-R1-Zero 等模型直接将强化学习应用于基...
强化学习,兼容性,Qwen
07月31日
0
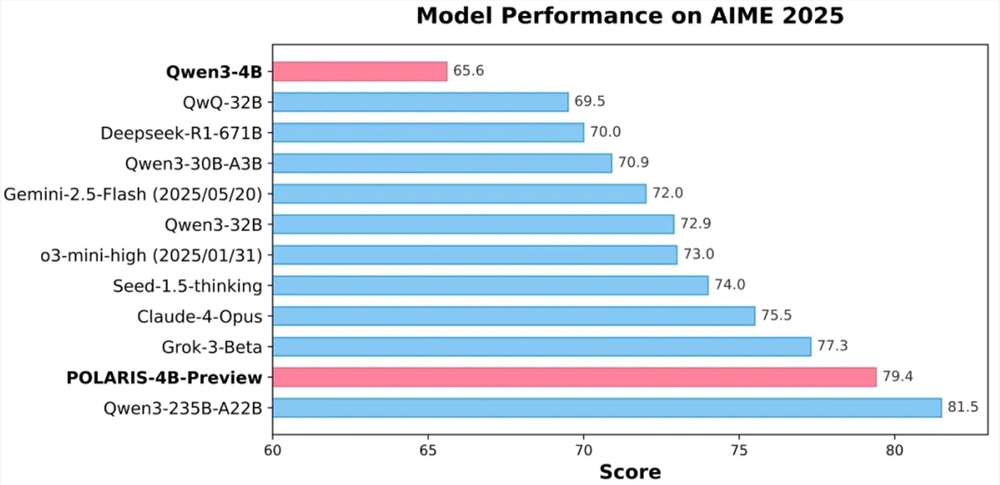
近日,字节跳动Seed团队携手香港大学与复旦大学,共同推出了创新的强化学习训练方法——POLARIS。该方法通过精心设计的Scaling RL策略,成功将小模型...
字节,强化学习,ARIS,开源,数学推理
07月31日
0
使用场景在模拟器中完成日常家务任务在复杂视频游戏中完成任务编写可执行代码产品特色高效解析代理的视觉和文本任务目标制定复杂的动作序列生成可执行代码处理广泛的任务,...
AI开发助手,AI代码生成,视觉语言编程,环境反馈,强化学习,GPT-4,模拟器,普通产品,开源,
08月01日
0
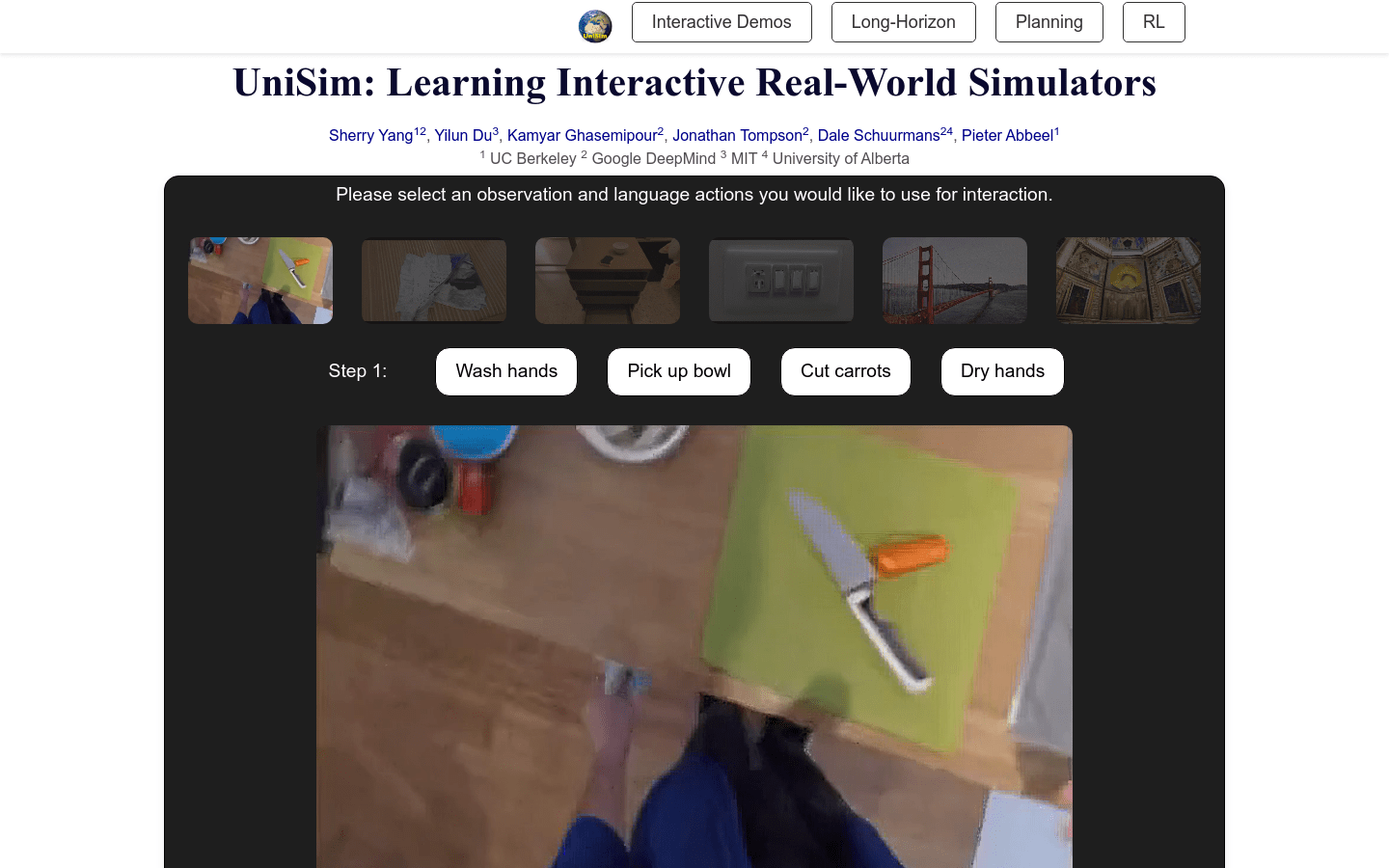
使用场景使用UniSim训练机器人进行长期规划利用UniSim模拟真实世界交互体验使用UniSim训练强化学习策略产品特色模拟真实世界交互体验训练高级视觉语言规...
AI模型,AI游戏创作,模拟器,交互式,强化学习,视觉语言规划器,决策优化,普通产品,开源,
08月01日
0
使用场景一个电子商务平台根据用户偏好调整商品展示顺序一个社交媒体应用根据用户兴趣推荐内容一个新闻应用根据用户阅读习惯调整新闻推送顺序产品特色实时UI个性化强化学...
个人助理,AI模型,AI,个性化,实时,用户体验,强化学习,普通产品
08月01日
0