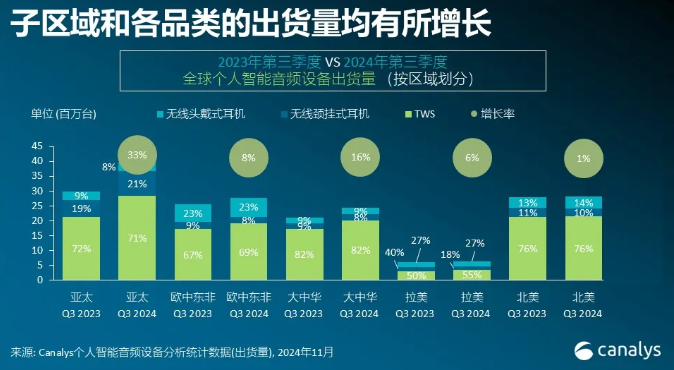
Canalys数据显示,2024年第三季度,全球个人智能音频设备市场迎来了强劲反弹,总出货量接近1.26亿件,较去年同期增长了15%。这一增长趋势表明,市场已成...
音频
07月30日
0
近日,aiOla 宣布推出一款开源的 AI 音频转录模型Whisper-NER ,该模型在转录过程中能够实时遮蔽敏感信息。aiOla 的新 Whisper-NE...
开源,AI,音频
07月30日
0
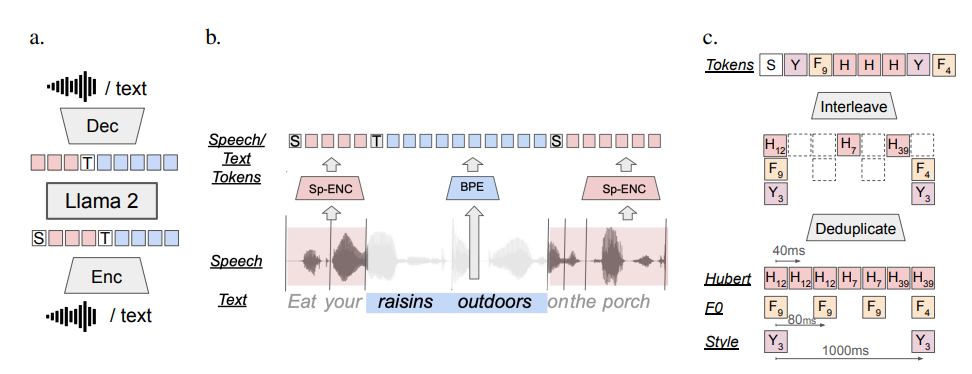
Meta AI近日重磅开源了名为SPIRIT LM的基础多模态语言模型,该模型能够自由混合文本和语音,为音频和文本的多模态任务打开了新的可能性。SPIRIT L...
Meta,音频,大模型,AI
07月30日
0
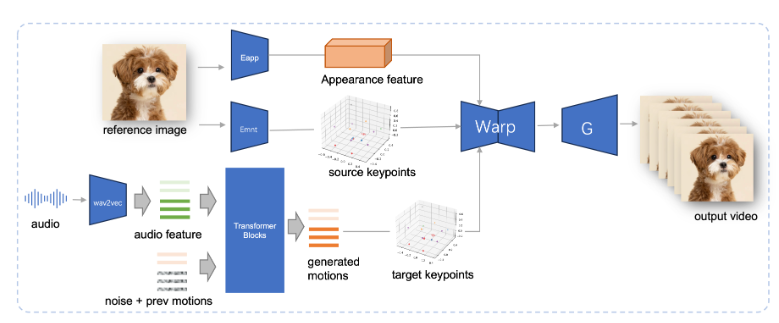
近日,研究人员提出了一种名为 JoyVASA 的新技术,旨在提升音频驱动的图像动画效果。随着深度学习和扩散模型的不断发展,音频驱动的人像动画在视频质量和嘴形同步...
音频,视频
07月30日
0
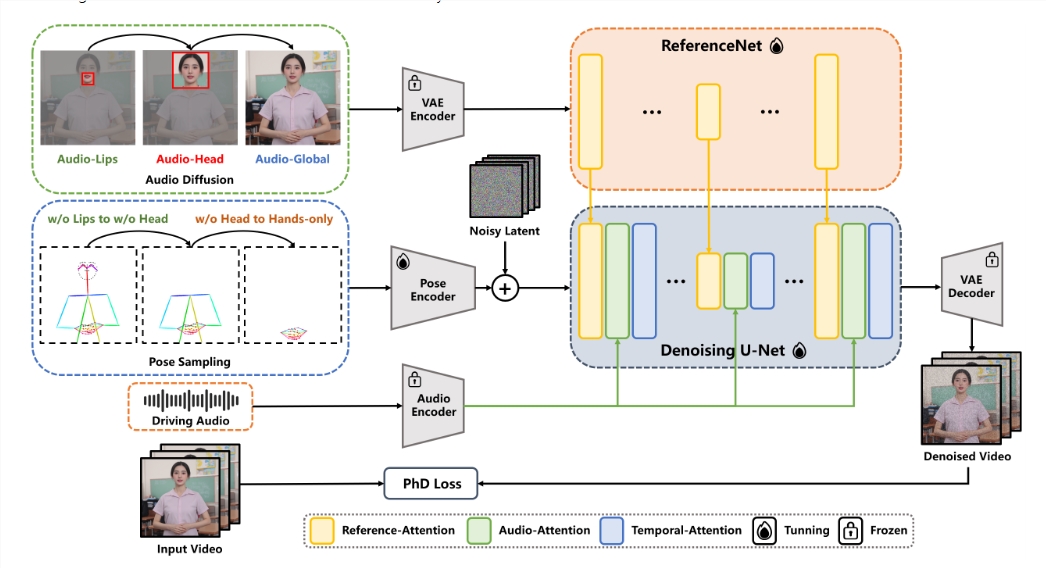
近年来,随着计算机视觉和动画技术的飞速发展,生成生动的人类动画逐渐成为研究热点。最新的研究成果 EchoMimicV2,利用参考图像、音频片段和手势序列,创造出...
音频,视频,数字人
07月30日
0
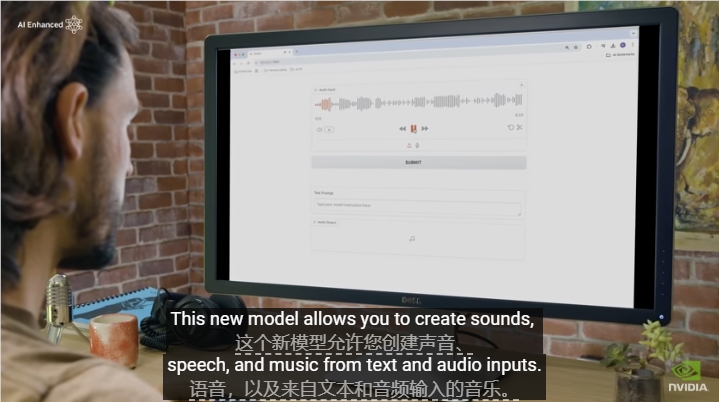
在音乐和声音创作领域,技术与创意的结合总是面临诸多挑战。现有的 AI 模型往往只擅长特定的任务,缺乏广泛的适应性,这使得 AI 在音乐制作中的辅助作用受限。为了...
英伟达,AI,音频,音乐,文本
07月30日
0
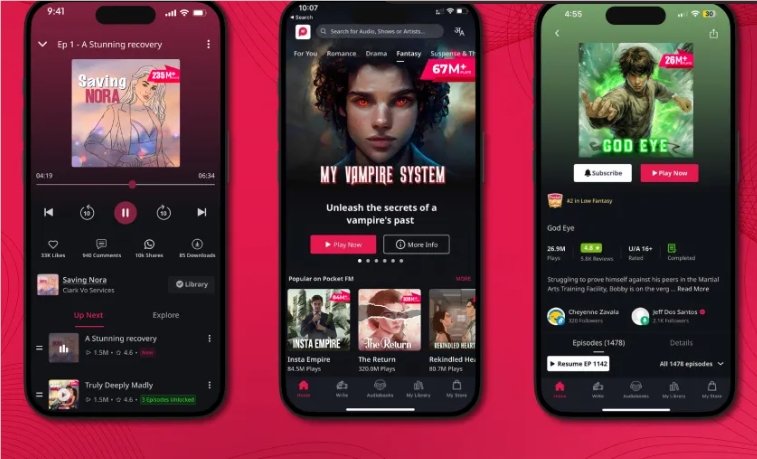
印度音频平台 Pocket FM 最近大展拳脚,现已拥有超过20万小时的丰富内容。然而,公司的首席执行官 Rohan Nayak 却觉得自己还有更大的提升空间。...
AI,音频,内容生产
07月30日
0
近日,来自伊利诺伊大学厄巴纳 - 香槟分校、Sony AI 及 Sony 集团公司的研究团队推出了一项名为 MMAudio 的新技术,该技术旨在通过多模态联合训...
AI,音频,视频,文本
07月30日
0
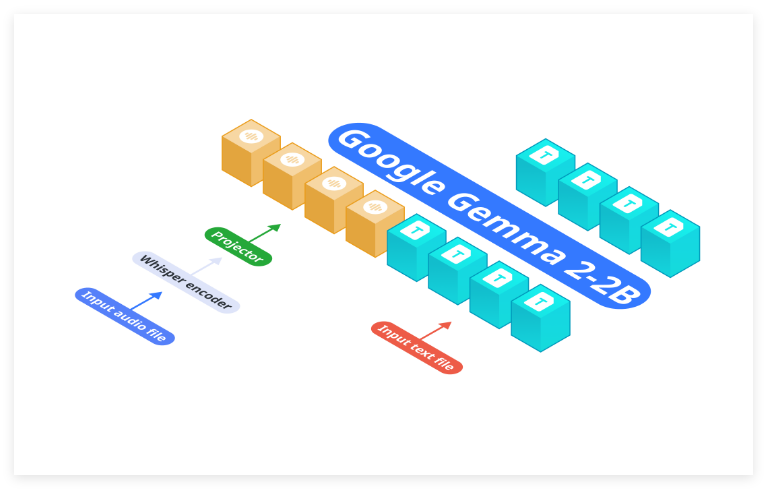
Nexa AI近日推出了其全新的OmniAudio-2.6B音频语言模型,旨在满足边缘设备的高效部署需求。与传统的将自动语音识别(ASR)和语言模型分开的架构不...
AI,音频,语言模型
07月30日
0
OpenAI 近日推出了其 API 的全新版本 o1模型,命名为 “o1-2024-12-17”,此版本带来了多个激动人心的新功能,包括智能函数调用、支持 JS...
OpenAI,AI,API,音频,图像分析
07月30日
0