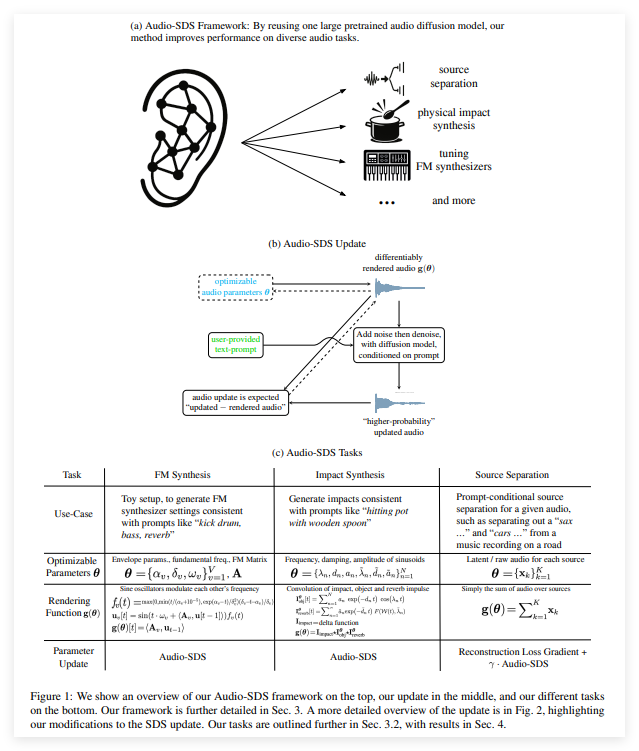
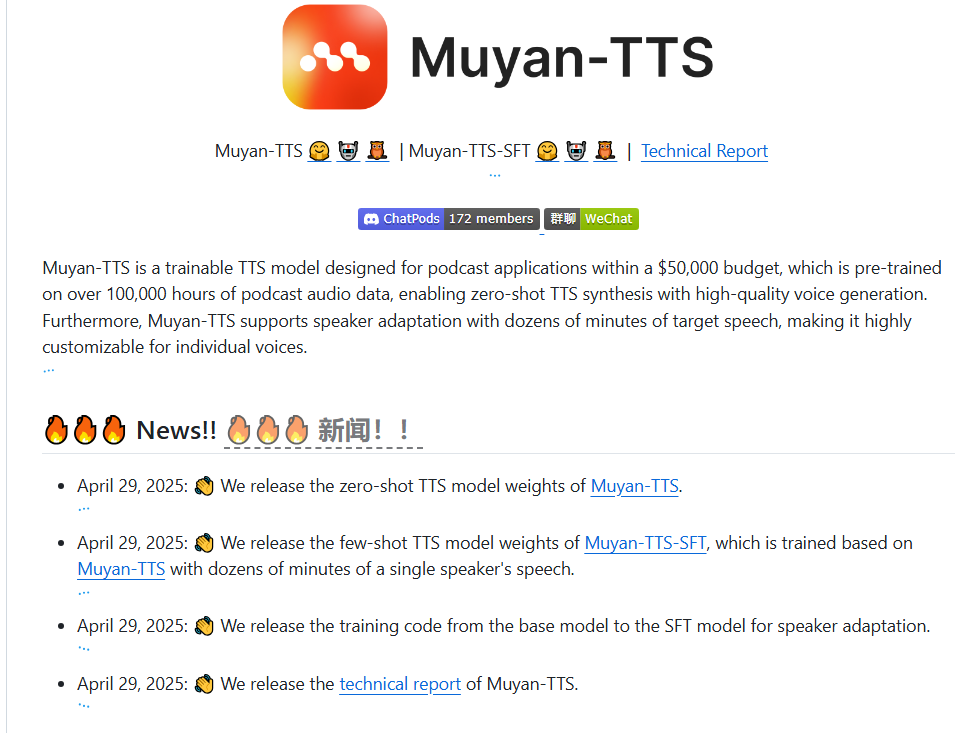
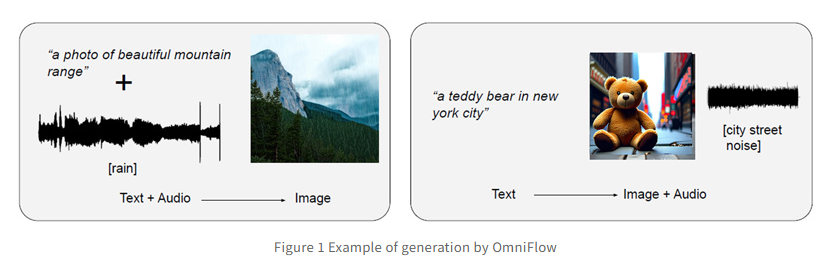
NVIDIA AI研究团队发布了一项突破性技术——Audio-SDS,将Score Distillation Sampling(SDS)技术扩展至文本条件音频扩...
NVIDIA,AI,音频
07月31日
0
开源语音合成迎来新突破!近日发布的开源 TTS 模型 Muyan-TTS 专为播客、有声书、长视频等场景设计,具备零样本语音合成、极速生成与高连贯性朗读能力,是...
音频,开源,上线,播客,有声书
07月31日
0
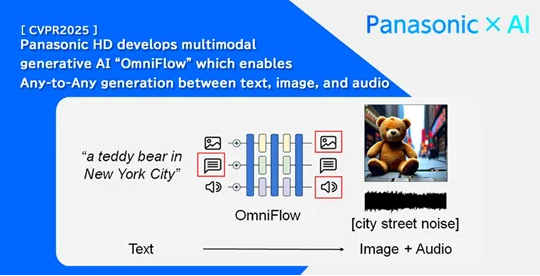
松下控股公司(Panasonic HD)联合美国松下研发公司(PRDCA)及加州大学洛杉矶分校(UCLA)的研究人员,成功开发出名为 “OmniFlow” 的多...
松下,Flow,多模态,AI,文本,音频
07月31日
0
在最近的开发更新中,谷歌更新了 Gemini2.5版本,标志着 AI 音频对话和生成技术的重大进步。Gemini2.5是一个多模态的 AI 系统,能够原生理解和...
音频,AI,对话
07月31日
0
随着人工智能技术的不断进步,多模态数据处理逐渐成为热门话题。近日,全球知名电器品牌松下推出了其最新研发的多模态大模型 ——OmniFlow。这一模型能够在文本、...
松下,Flow,多模态,大模型,文本,音频
07月31日
0
浙江大学与阿里巴巴联合推出全新音频驱动模型OmniAvatar,标志着数字人技术迈向新高度。该模型以音频为驱动,可生成自然流畅的全身数字人视频,尤其在歌唱场景下...
阿里,音频,数字人
07月31日
0
在人工智能领域,尤其是生成式对抗网络(AIGC)方面的不断进展,语音交互已成为一个重要的研究方向。传统的大语言模型(LLM)主要专注于文本处理,无法直接生成自然...
开源,音频,大模型
07月31日
0
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产...
AI,百度,绘想,Muse,阿里,音频,数字人
07月31日
0
Stability AI联合芯片巨头Arm正式开源Stable Audio Open Small,一款专为移动设备优化的341M参数文本到音频生成模型。这款轻量...
Stability AI,Stable Audio,AI,开源,音频
07月31日
0
近日,阿里语音AI团队宣布开源全球首个支持链式推理的音频生成模型ThinkSound,该模型通过引入思维链(Chain-of-Thought)技术,突破传统视频...
阿里,通义,开源,音频
07月31日
0