使用场景
自动生成有声读物的背景音效和对话
为视频内容自动添加旁白和音效
创建虚拟角色的声音,用于游戏或动画
产品特色
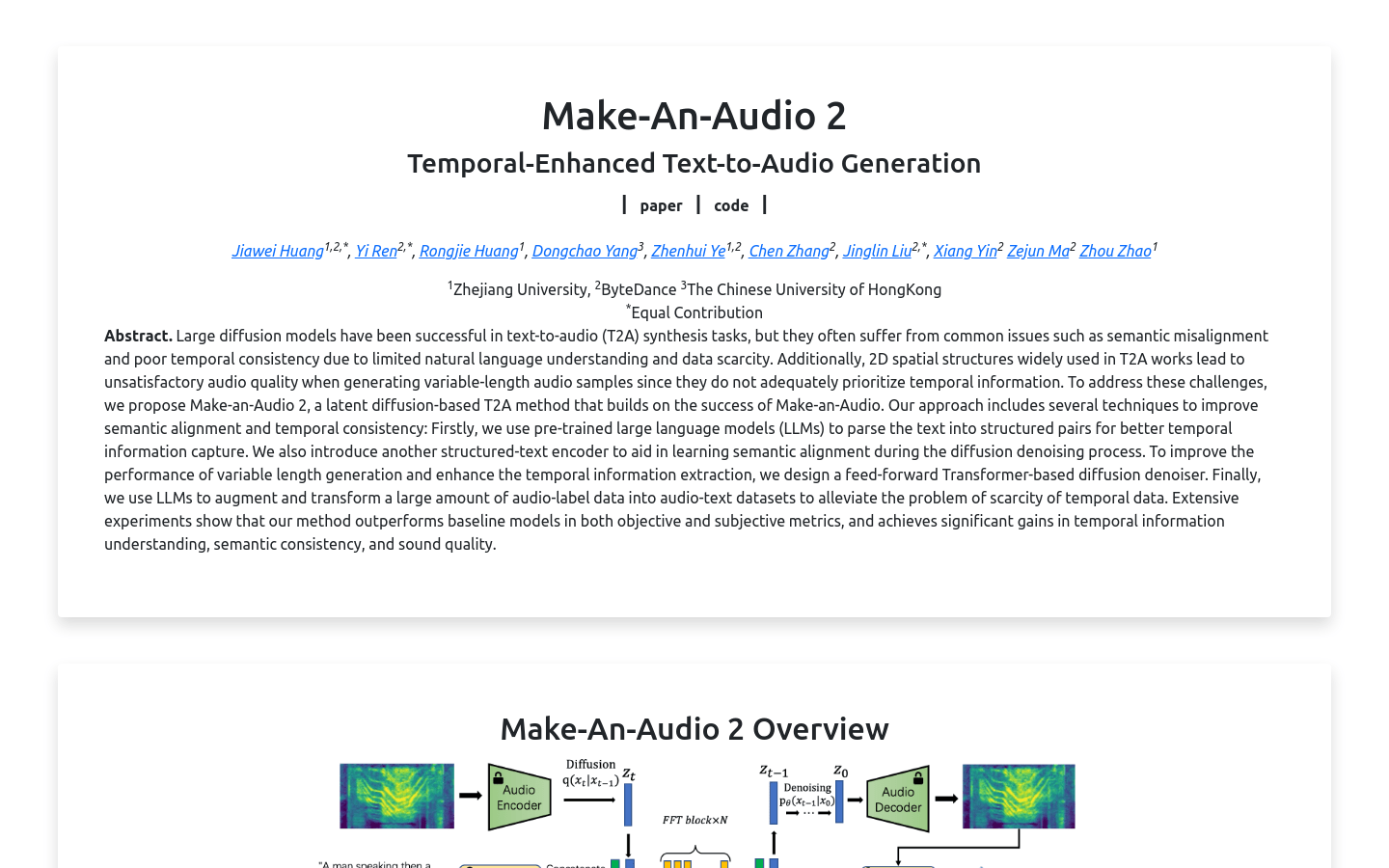
使用预训练的大型语言模型(LLMs)解析文本,优化时间信息捕获
引入结构化文本编码器,辅助学习扩散去噪过程中的语义对齐
设计基于前馈Transformer的扩散去噪器,改善变长音频生成性能
利用LLMs增强和转换音频标签数据,缓解时间数据稀缺问题
在客观和主观指标上超越基线模型,显著提升时间信息理解、语义一致性和声音质量
使用教程
步骤1: 准备自然语言文本作为输入
步骤2: 使用Make-An-Audio 2的Text Encoder解析文本
步骤3: 结构化文本编码器辅助学习语义对齐
步骤4: 利用扩散去噪器生成音频
步骤5: 调整生成音频的长度和时间控制
步骤6: 根据需要修改结构化输入以精确控制时间
步骤7: 生成最终的音频输出










