使用场景
研究人员使用该排行榜来比较不同LLMs在特定编程任务上的表现。
开发者利用排行榜数据选择适合其应用场景的AI模型。
教育机构可能使用该平台作为教学资源,展示AI技术的最新进展。
产品特色
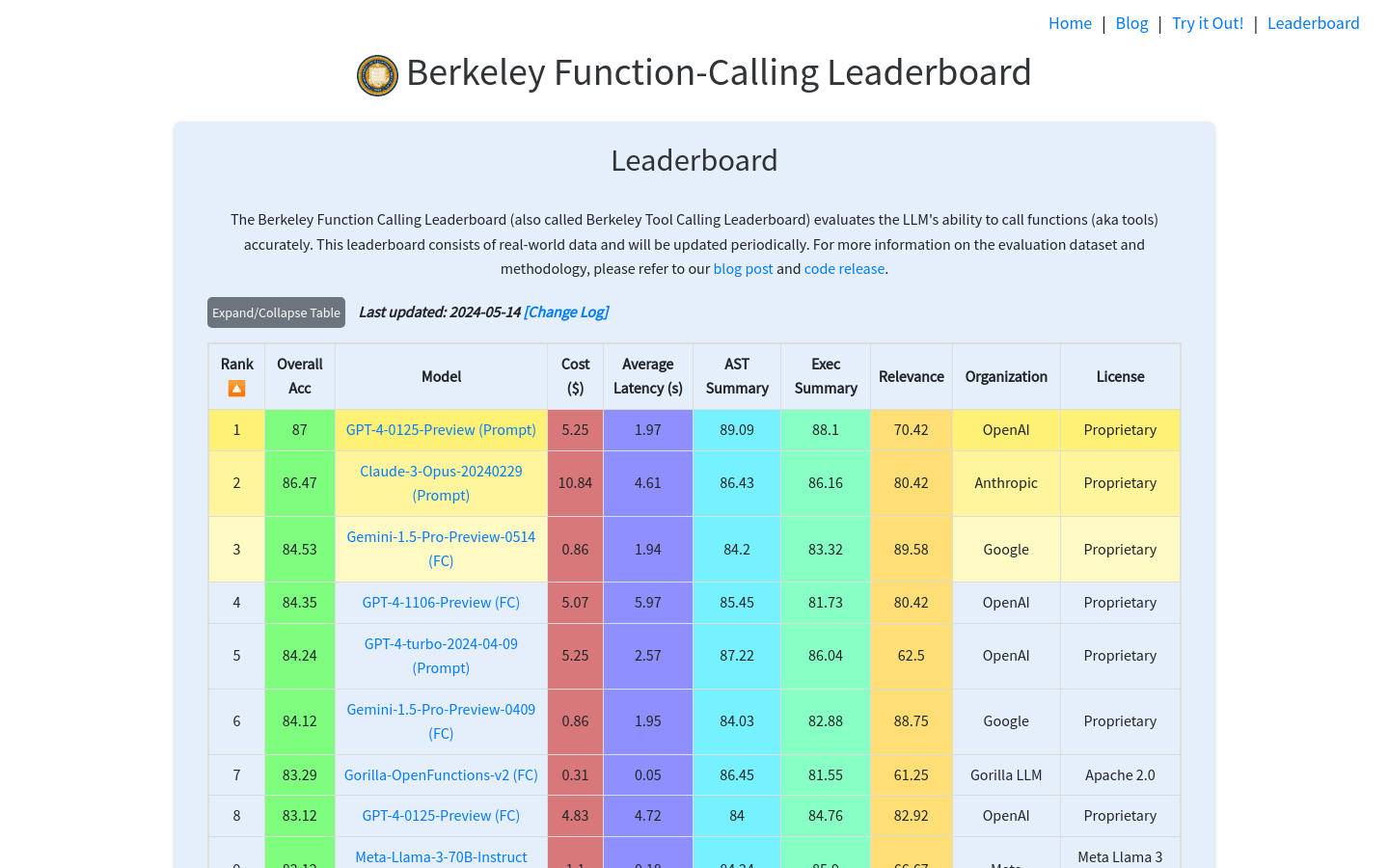
提供大型语言模型函数调用能力的评估
包含真实世界数据的评估集
排行榜定期更新,反映最新技术进展
提供详细的错误类型分析,帮助用户理解模型的优缺点
支持模型间比较,便于用户选择最合适的模型
提供模型成本和延迟的估算,帮助用户做出经济高效的选择
使用教程
访问Berkeley Function-Calling Leaderboard网站。
查看当前排行榜,了解各模型的得分和排名。
点击感兴趣的模型,获取该模型的详细信息和评估数据。
使用错误类型分析工具,了解模型在不同错误类型上的表现。
参考成本和延迟估算,评估模型的经济性和响应速度。
如果需要,可以通过网站提供的联系方式,提交自己的模型或贡献测试案例。










