使用场景
开发者使用该模型进行多语言的聊天机器人开发。
数据科学家利用模型的长文本推理能力进行大规模数据分析。
研究人员通过模型的代码执行功能进行算法验证和测试。
产品特色
多轮对话能力,能够进行连贯的交互。
网页浏览功能,可以获取和理解网页内容。
代码执行能力,能够运行和理解代码。
自定义工具调用,可以接入和使用自定义工具或API。
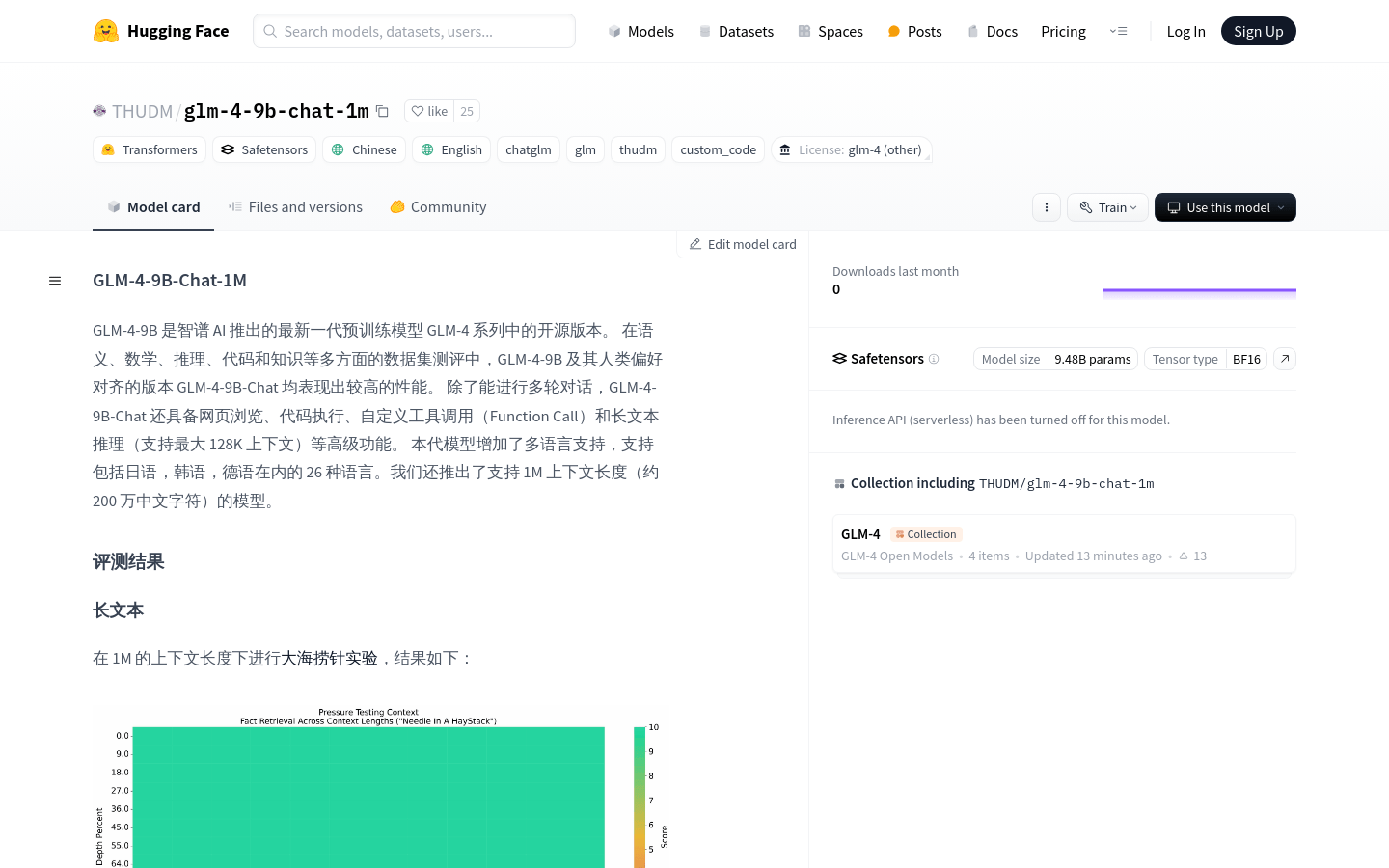
长文本推理,支持最大128K上下文,适合处理大量数据。
多语言支持,包括日语、韩语、德语等26种语言。
1M上下文长度支持,约200万中文字符,适合长文本处理。
使用教程
步骤一:导入必要的库,如torch和transformers。
步骤二:使用AutoTokenizer.from_pretrained()方法加载模型的tokenizer。
步骤三:准备输入数据,使用tokenizer.apply_chat_template()方法格式化输入。
步骤四:将输入数据转换为模型需要的格式,如使用to(device)方法将其转换为PyTorch张量。
步骤五:加载模型,使用AutoModelForCausalLM.from_pretrained()方法。
步骤六:设置生成参数,如max_length和do_sample。
步骤七:调用model.generate()方法生成输出。
步骤八:使用tokenizer.decode()方法将输出解码为可读文本。










