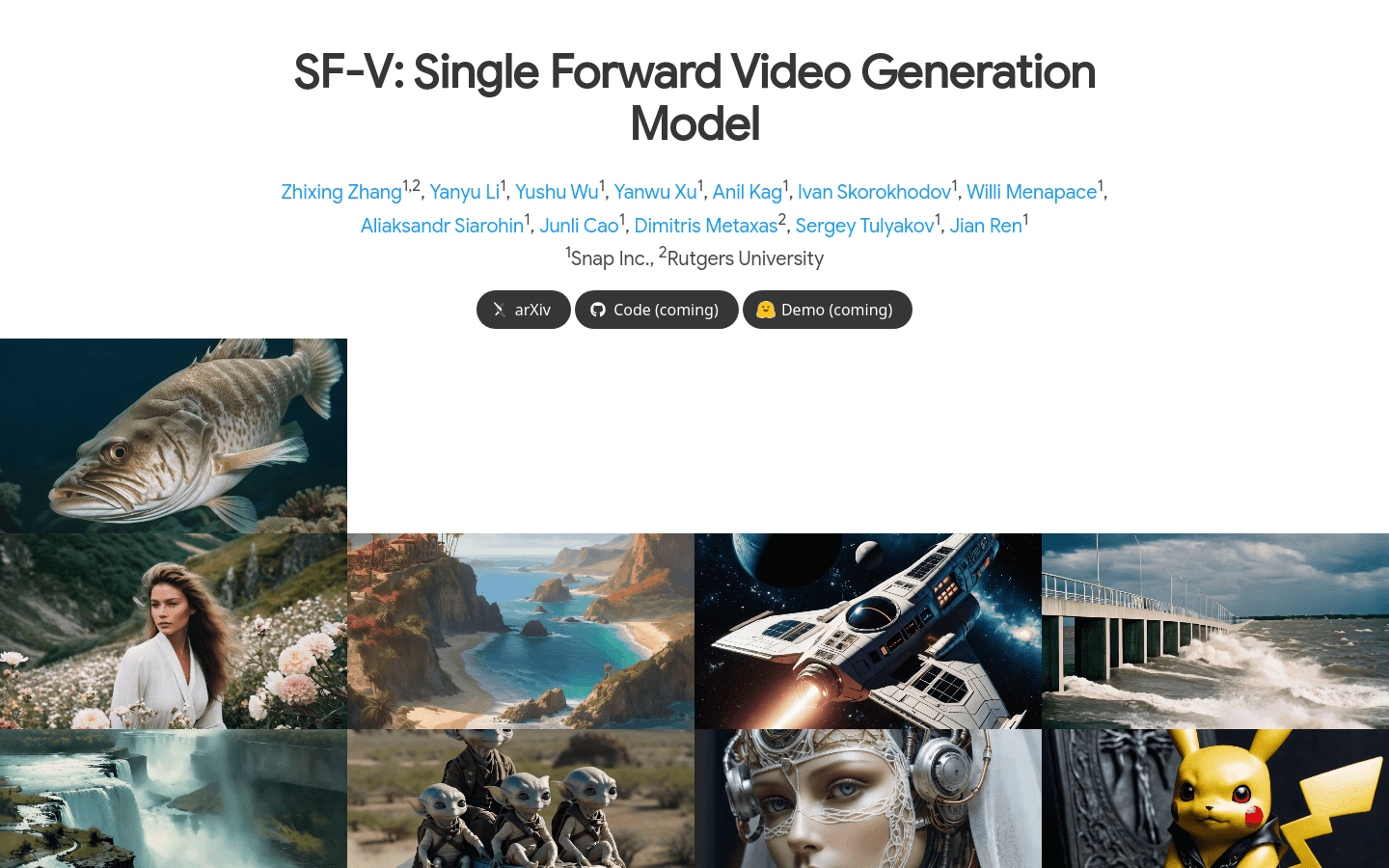
使用场景
用于生成虚拟现实环境中的动态背景视频。
在游戏开发中快速生成动画角色的动画序列。
为电影后期制作提供高质量的视频素材合成。
产品特色
利用对抗训练对预训练的视频扩散模型进行微调。
通过单步前向传播合成高质量视频,捕捉视频数据的时间和空间依赖性。
与现有技术相比,实现了大约23倍的速度提升和更好的生成质量。
初始化生成器和鉴别器使用预训练的图像到视频扩散模型的权重。
在训练过程中,冻结UNet的编码器部分,并仅更新空间和时间鉴别器头部的参数。
提供视频比较结果和消融分析,展示方法的有效性。
使用教程
1. 下载并安装所需的软件环境和依赖库。
2. 访问SF-V模型的网页,了解其基本原理和功能。
3. 根据提供的代码(coming)和演示(coming),设置实验环境。
4. 利用SF-V模型的初始化参数,配置生成器和鉴别器。
5. 通过对抗训练对模型进行微调,优化视频生成质量。
6. 使用模型进行视频合成,观察并评估生成的视频质量。
7. 根据需要调整模型参数,以适应不同的视频合成任务。










