使用场景
移动应用开发者使用PowerInfer-2在智能手机上部署个性化推荐系统
企业利用PowerInfer-2在移动设备上实现客户服务自动化
研究机构使用PowerInfer-2在移动设备上进行实时语言翻译和交互
产品特色
支持高达47B参数的MoE模型
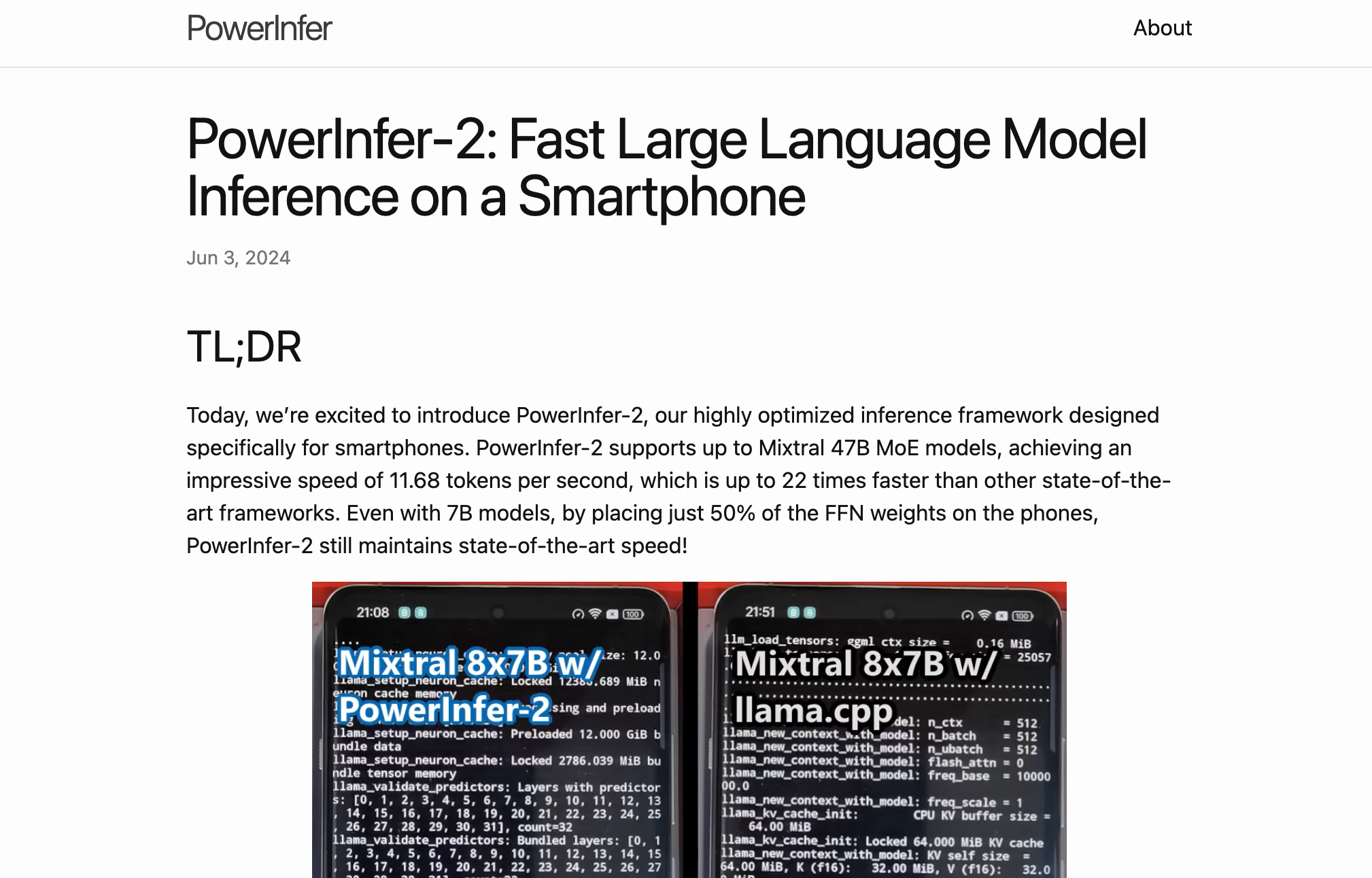
实现每秒11.68个token的推理速度
异构计算优化,动态调整计算单元大小
I/O-Compute流水线技术,最大化数据加载与计算的重叠
显著减少内存使用,提高推理速度
适用于智能手机,增强数据隐私和性能
模型系统共同设计,确保模型的可预测稀疏性
使用教程
1. 访问PowerInfer-2的官方网站并下载框架
2. 根据文档说明,集成PowerInfer-2到移动应用开发项目中
3. 选择适合的模型并配置模型参数,确保模型的稀疏性
4. 利用PowerInfer-2的API进行模型推理,优化推理速度和内存使用
5. 在移动设备上测试推理效果,确保应用性能和用户体验
6. 根据反馈进行调整,优化模型部署和推理过程










