使用场景
研究人员使用 MDLM 进行长文本的自动摘要生成。
开发者利用 MDLM 在聊天机器人中生成更加自然和流畅的对话。
教育机构采用 MDLM 生成教学材料和课程内容。
产品特色
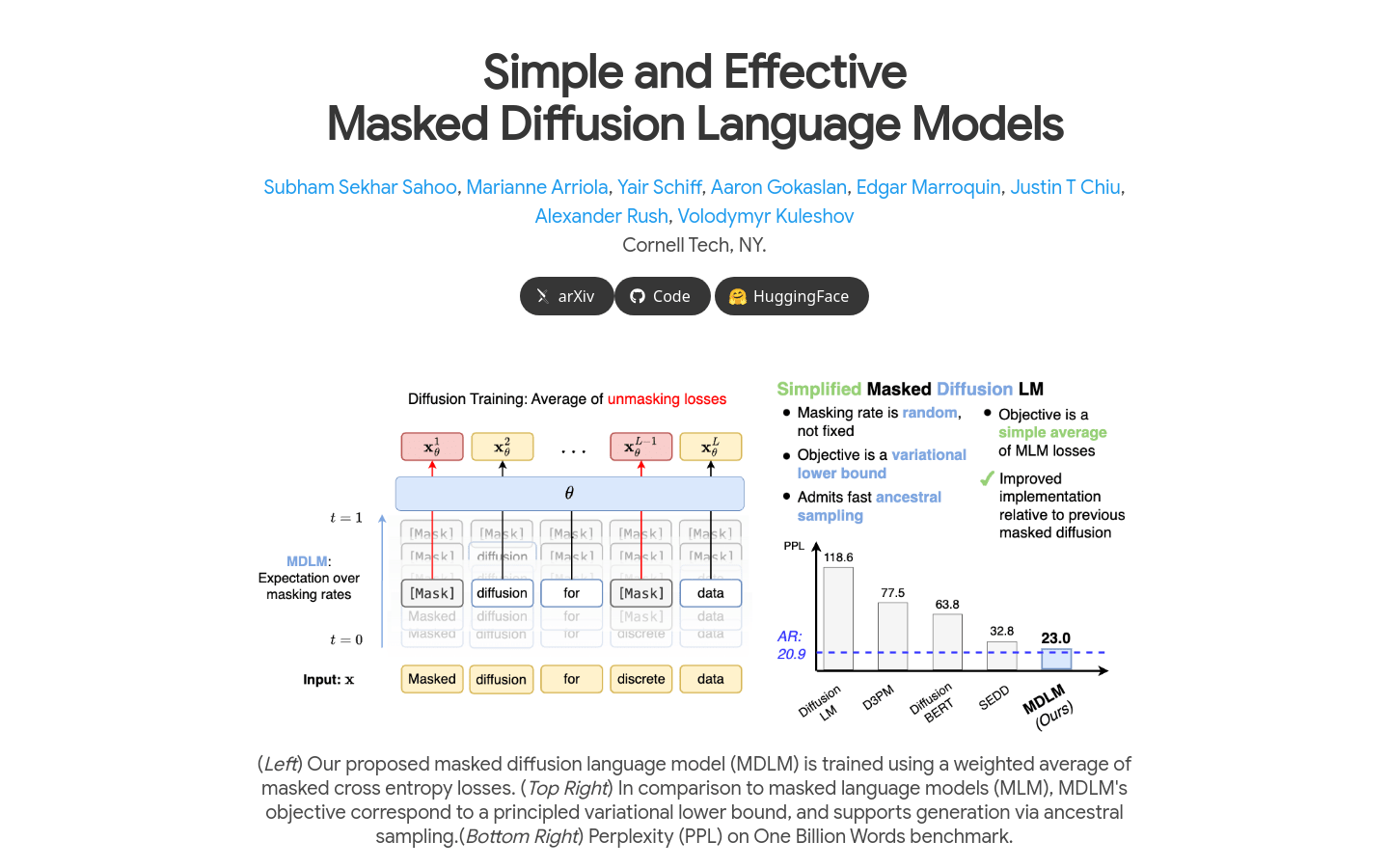
使用加权平均遮蔽交叉熵损失进行训练。
与自回归方法相比,MDLM 的目标对应于一个原理性的变分下界。
支持通过祖先采样进行文本生成。
在 One Billion Words 基准测试中表现出较低的困惑度。
通过现代工程实践训练的 MDLM 在语言建模中达到了新的最佳状态。
MDLM 可以训练编码器仅语言模型,允许高效的采样器。
使用教程
第一步:了解 MDLM 的基本原理和功能。
第二步:获取 MDLM 模型和相关的训练代码。
第三步:准备训练数据集,包括遮蔽和未遮蔽的文本样本。
第四步:使用 MDLM 进行模型训练,调整参数以优化性能。
第五步:在特定任务上测试 MDLM,评估生成文本的质量。
第六步:将训练好的 MDLM 模型集成到实际应用中。










