使用场景
用于训练SteerLM回归奖励模型,提高对话系统在特定任务上的表现。
作为研究项目的一部分,分析和比较不同模型在处理多轮对话时的响应质量。
在教育领域,帮助学生理解如何通过机器学习技术来改进语言模型的响应。
产品特色
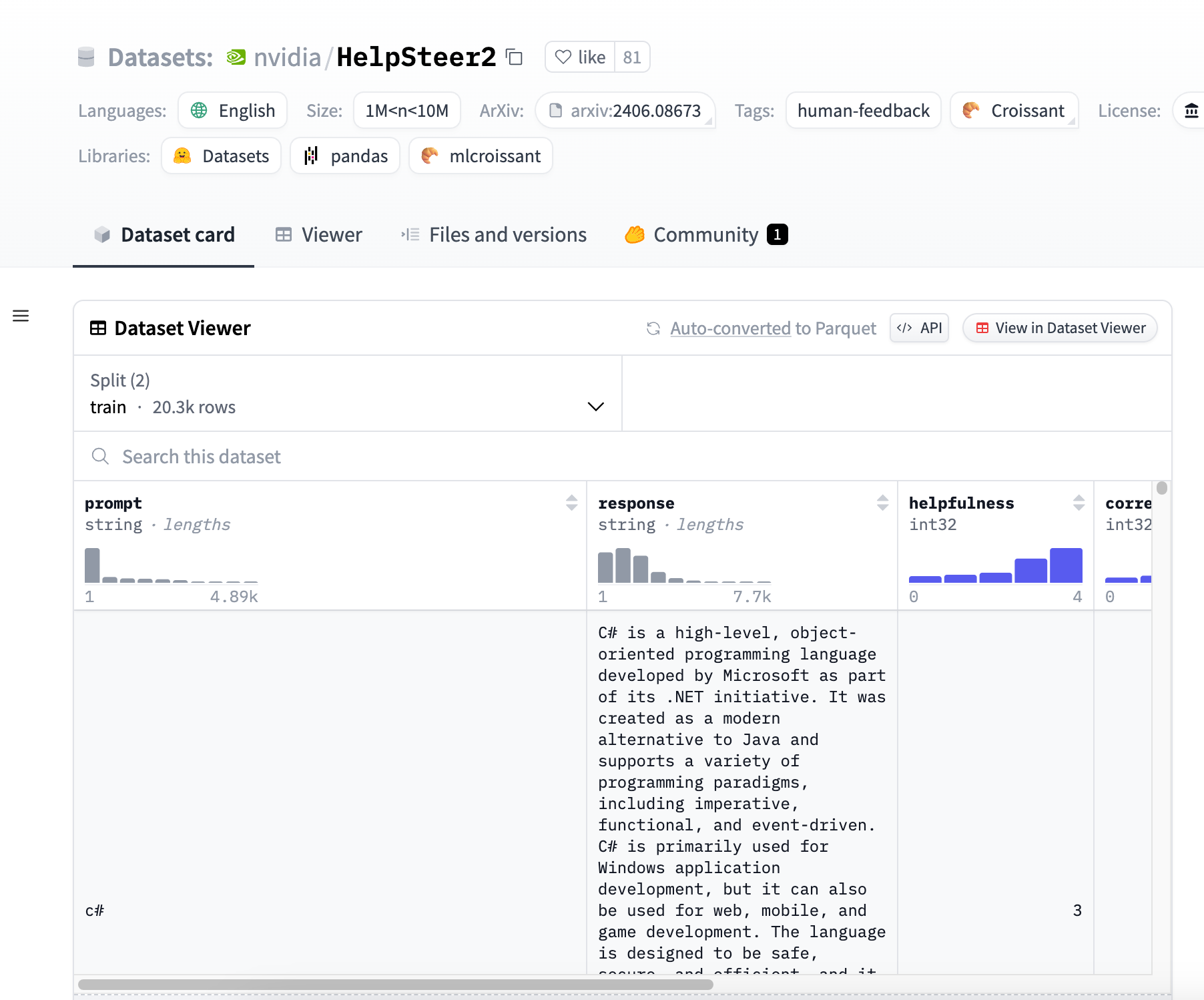
包含21,362个样本,每个样本包括一个提示、一个响应以及五个人类标注的属性评分。
属性评分包括帮助性、正确性、连贯性、复杂性和冗余度。
支持多轮对话的样本,可以用于基于偏好对的DPO或Preference RM训练。
响应由10种不同的内部大型语言模型生成,提供多样化但合理的响应。
使用Scale AI进行标注,确保了数据集的质量和一致性。
数据集遵循CC-BY-4.0许可,可以自由使用和分发。
使用教程
步骤1:访问Hugging Face官网并搜索HelpSteer2数据集。
步骤2:下载数据集,并使用适当的工具或库加载数据集。
步骤3:根据项目需求,选择数据集中的特定样本或属性进行分析。
步骤4:使用数据集训练或优化你的语言模型,监控模型在各个属性上的表现。
步骤5:调整模型参数,根据需要改进模型的训练过程。
步骤6:评估模型性能,确保其在帮助性、正确性和其他关键属性上达到预期标准。
步骤7:将训练好的模型部署到实际应用中,如聊天机器人或虚拟助手。










