使用场景
使用MINT-1T预训练的XGen-MM多模态模型在图像说明和视觉问答任务中表现优异。
在多学科多模态理解和推理基准(MMMU)上,MINT-1T在科学和技术领域的表现显著优于其他数据集。
Idefics2架构下的MINT-1T在图像字幕生成和视觉问答任务上展现出卓越的性能。
产品特色
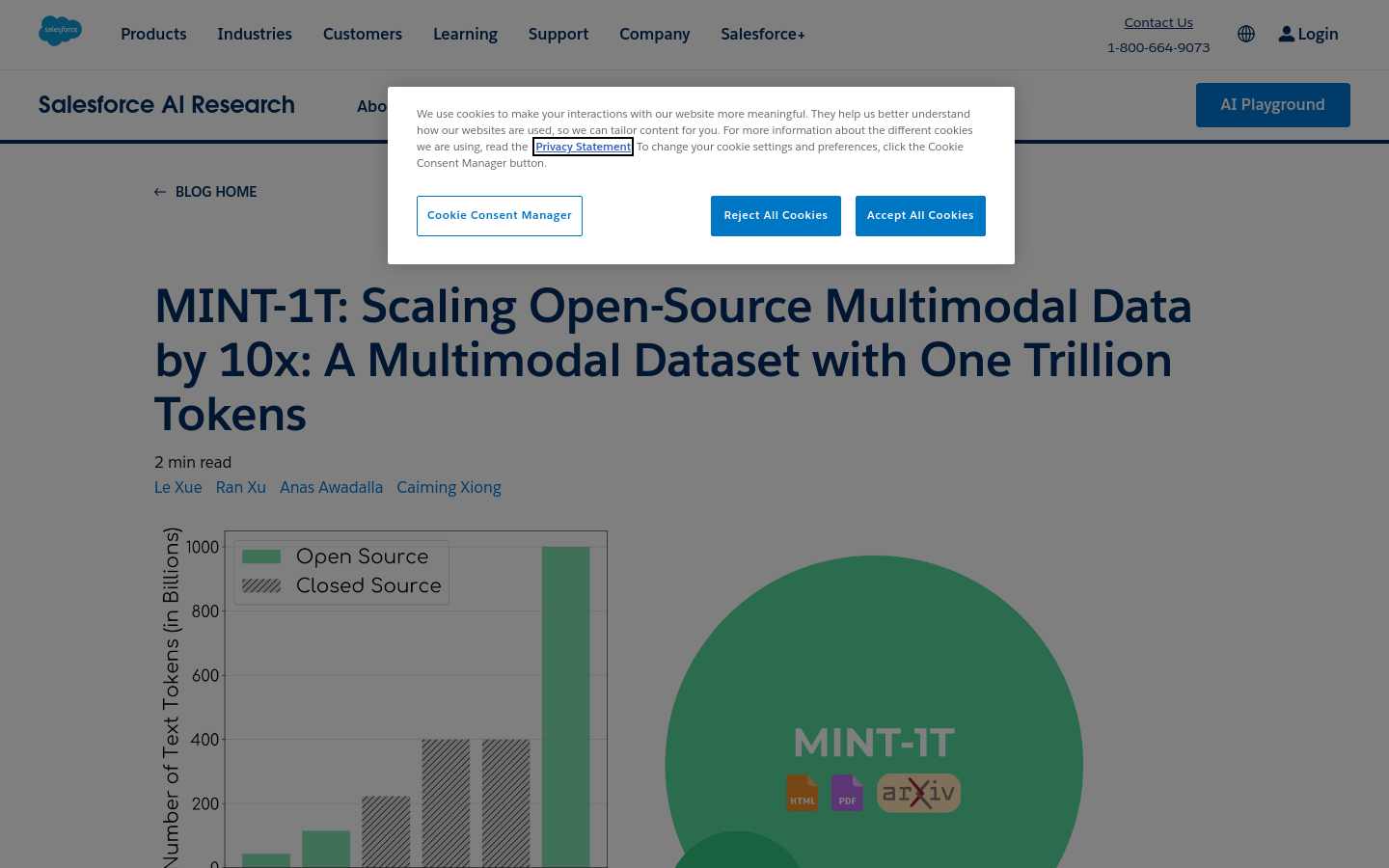
规模大:数据量达到一万亿个Token,是现有数据集的10倍。
多样性:包含HTML、PDF和ArXiv论文等多种文档类型。
高质量:通过严格的数据过滤和去重处理,确保数据质量。
跨模态推理:能够训练跨图像和文本模式推理的大型多模态模型。
领域覆盖广:文档覆盖科学、技术、人文等多个领域。
上下文学习性能强:在不同示例数量下均展现出优越的学习性能。
多任务表现优异:在图像字幕生成和视觉问答等任务上表现突出。
使用教程
1. 访问MINT-1T数据集的开源页面,了解数据集的基本信息和特点。
2. 下载数据集,根据研究或开发需求选择合适的数据子集。
3. 使用数据集进行模型预训练或微调,以适应特定的多模态任务。
4. 在图像字幕生成、视觉问答等任务上测试模型性能。
5. 分析模型在不同领域和任务上的表现,优化模型结构和参数。
6. 根据实验结果,进一步探索数据集的潜力和应用范围。
7. 发表研究成果,分享使用MINT-1T数据集的经验和发现。










