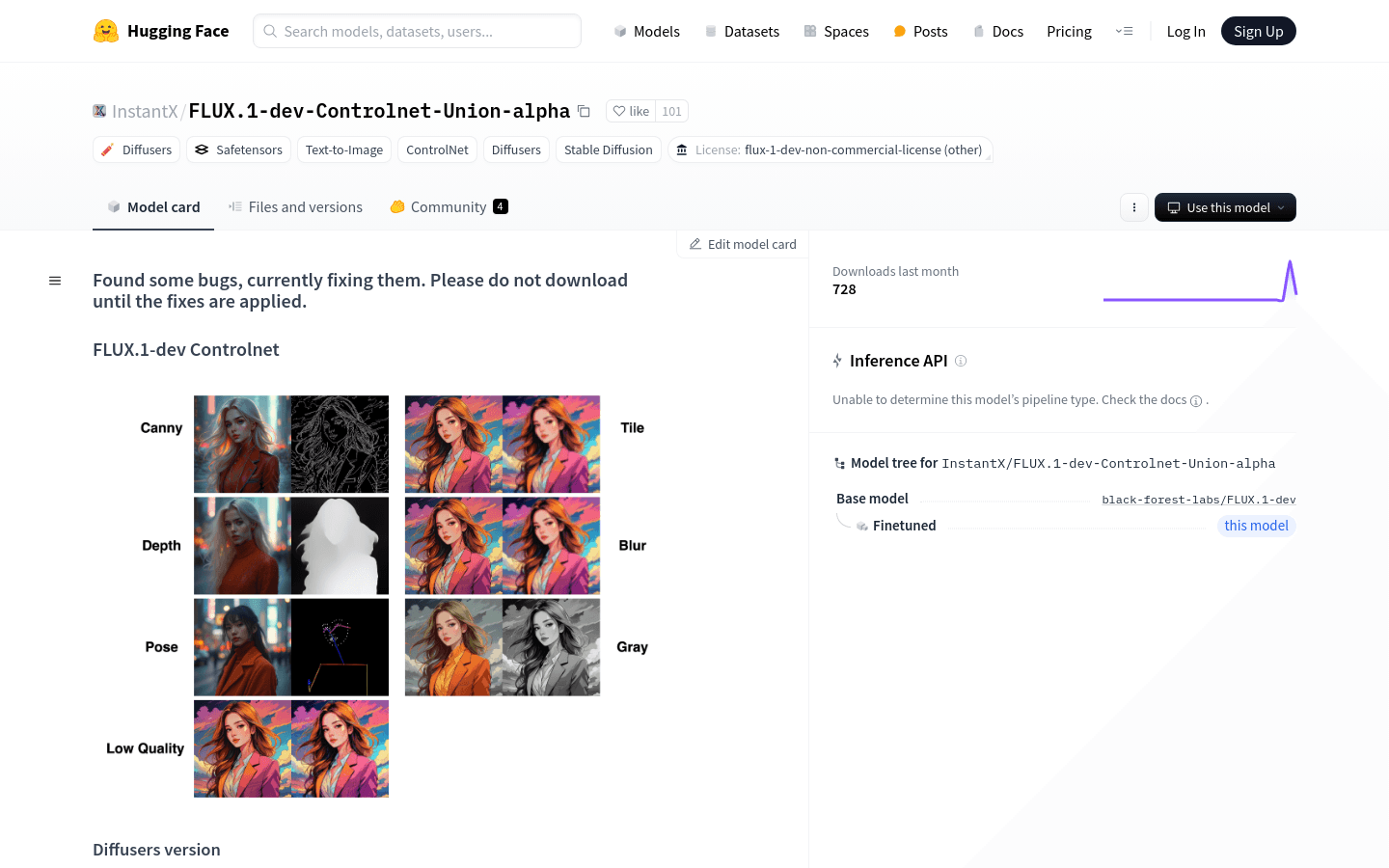
使用场景
设计师使用该模型根据文本描述生成具有未来感的城市女孩图像。
研究人员利用模型进行图像生成的实验,探索不同控制模式对生成结果的影响。
开发者将模型集成到应用程序中,为用户提供基于文本描述的个性化图像生成服务。
产品特色
支持多种控制模式,如canny、tile、depth、blur、pose、gray和lq。
使用torch和diffusers库进行模型加载和图像生成。
提供高分辨率图像生成,支持自定义宽度和高度。
允许通过控制网调节条件比例,以影响生成图像的特定特征。
支持通过种子值进行图像生成的复现。
提供Demo代码示例,方便用户快速理解和使用模型。
使用教程
1. 安装必要的库,如torch和diffusers。
2. 从Hugging Face加载基础模型和ControlNet模型。
3. 设置图像生成的参数,包括宽度、高度和控制网调节比例。
4. 选择控制模式和相应的控制图像。
5. 定义文本提示,描述希望生成的图像内容。
6. 调用模型生成图像,并保存结果。










