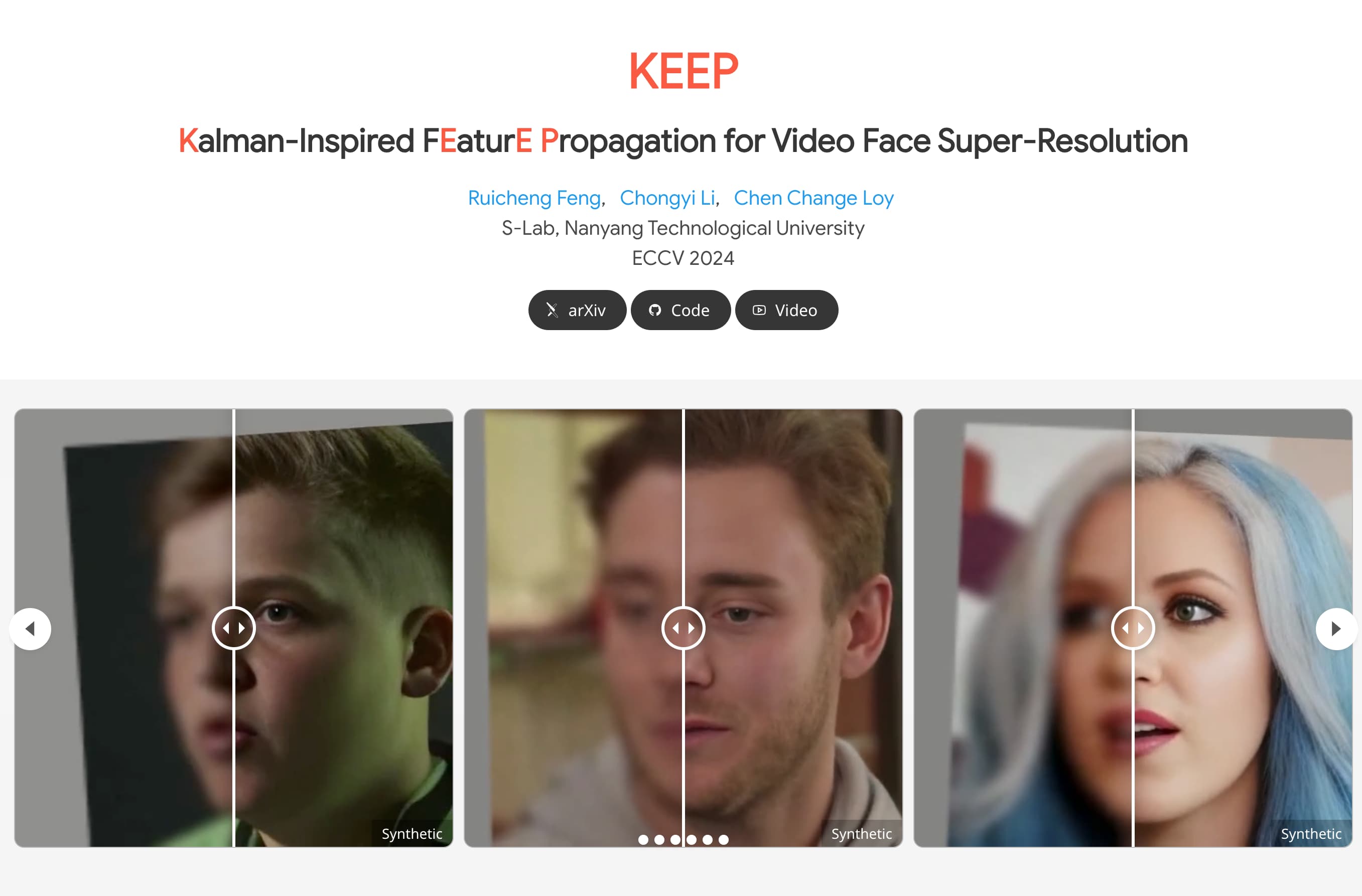
使用场景
在安全监控领域,通过KEEP模型提高视频监控中人脸的识别精度。
在娱乐行业中,用于改善老旧视频资料中的人脸清晰度,提升观看体验。
在社交媒体上,用户可以利用KEEP模型增强自己上传视频的人脸清晰度。
产品特色
编码器和解码器构建的VQGAN生成模型,用于生成高质量的超分辨率图像。
Kalman滤波网络,用于整合Kalman滤波原理,促进时间信息传播并保持稳定的潜在代码先验。
当前帧的观测状态和前一帧的预测状态通过Kalman增益网络进行递归融合,形成当前状态的更准确后验估计。
跨帧注意力(CFA)层,用于进一步促进局部时间一致性,规范信息传播。
证据累积和增强时间一致性,适用于人脸视频超分辨率。
在ECCV 2024上发表,展示了在视频帧中捕捉人脸细节方面的有效性。
使用教程
1. 访问KEEP模型的官方网页以获取更多信息和代码。
2. 阅读相关的研究论文,了解KEEP模型的工作原理和应用场景。
3. 下载并安装必要的软件环境,以运行KEEP模型。
4. 准备需要进行超分辨率处理的视频人脸数据集。
5. 根据文档指导,配置模型参数并加载数据集。
6. 运行KEEP模型,观察并分析超分辨率处理后的结果。
7. 根据需要调整模型参数,以优化超分辨率效果。










