使用场景
研究人员使用 Llama3-s v0.2 进行语音识别研究,提高语音数据集的处理效率。
开发者利用该模型集成到智能助手应用中,增强语音交互功能。
教育机构采用 Llama3-s v0.2 进行语音教学辅助,提升语言学习体验。
产品特色
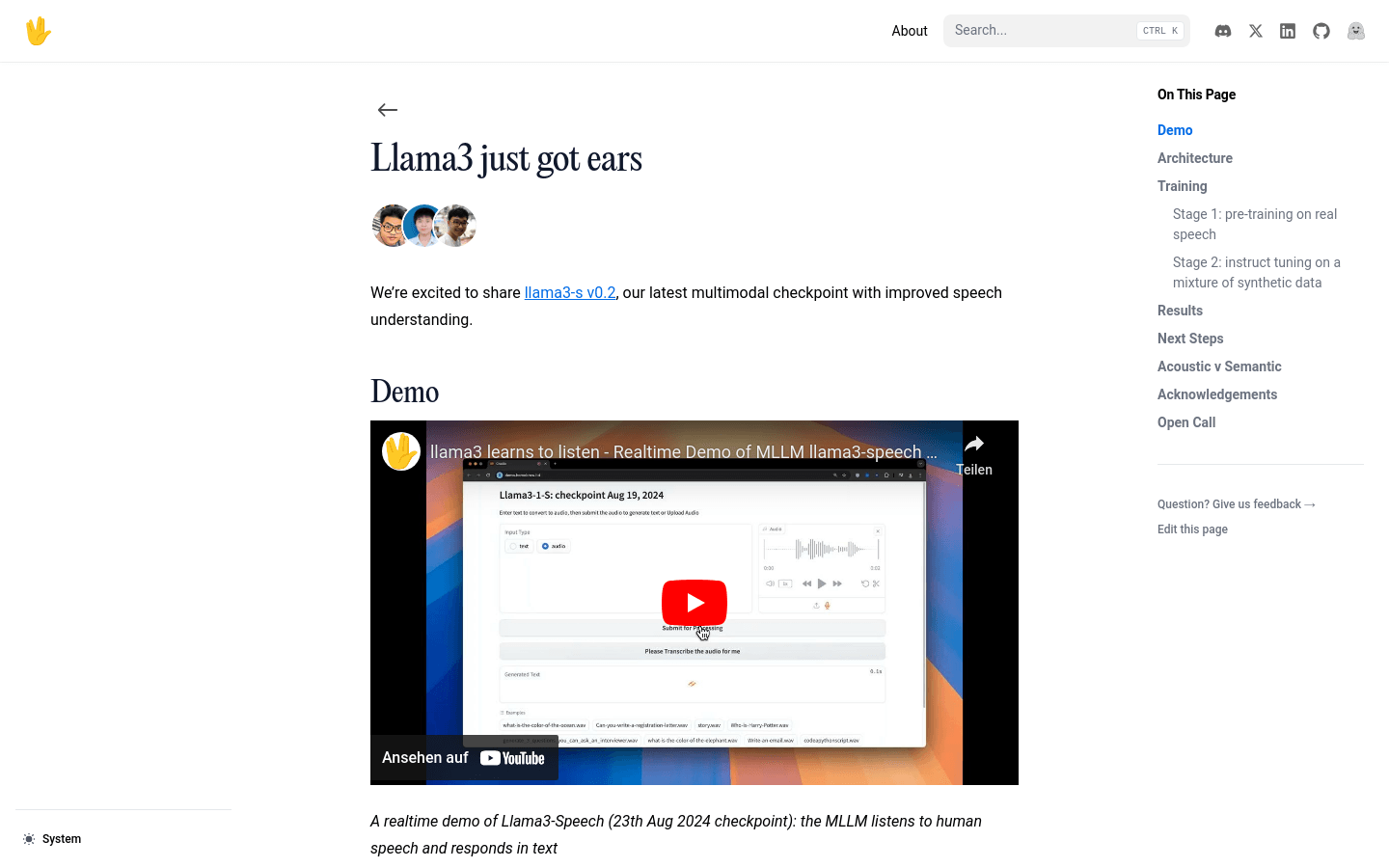
实时演示:MLLM 听取人类语音并用文本回应。
多语音理解基准测试表现:在多个语音理解基准测试中稳定表现。
早期融合语义标记:利用语义标记简化模型结构,提高压缩效率。
预训练:使用 MLS-10k 数据集进行连续语音的预训练,增强模型泛化能力。
指导调整:使用混合合成数据进行指导调整,提高模型对语音指令的响应能力。
模型性能评估:通过 AudioBench 等基准测试评估模型性能。
持续研究与更新:团队计划通过持续研究和更新,解决模型当前的限制和挑战。
使用教程
访问 Homebrew 官方网站并注册账户。
选择 Llama3-s v0.2 模型并了解其功能和特点。
通过提供的实时演示链接,体验模型的语音识别和文本回应功能。
根据需要,下载模型代码或使用自托管演示进行进一步的测试和开发。
参与社区讨论,获取反馈,并根据指导调整模型以适应特定应用场景。
关注 Homebrew 的更新,以获取模型性能的提升和新功能的添加。










