使用场景
用于图像描述生成,提高图像内容理解的准确性。
在数学和编程问题解答中,提供逐步的数学推理。
用于OCR任务,识别图像中的文本并进行处理。
产品特色
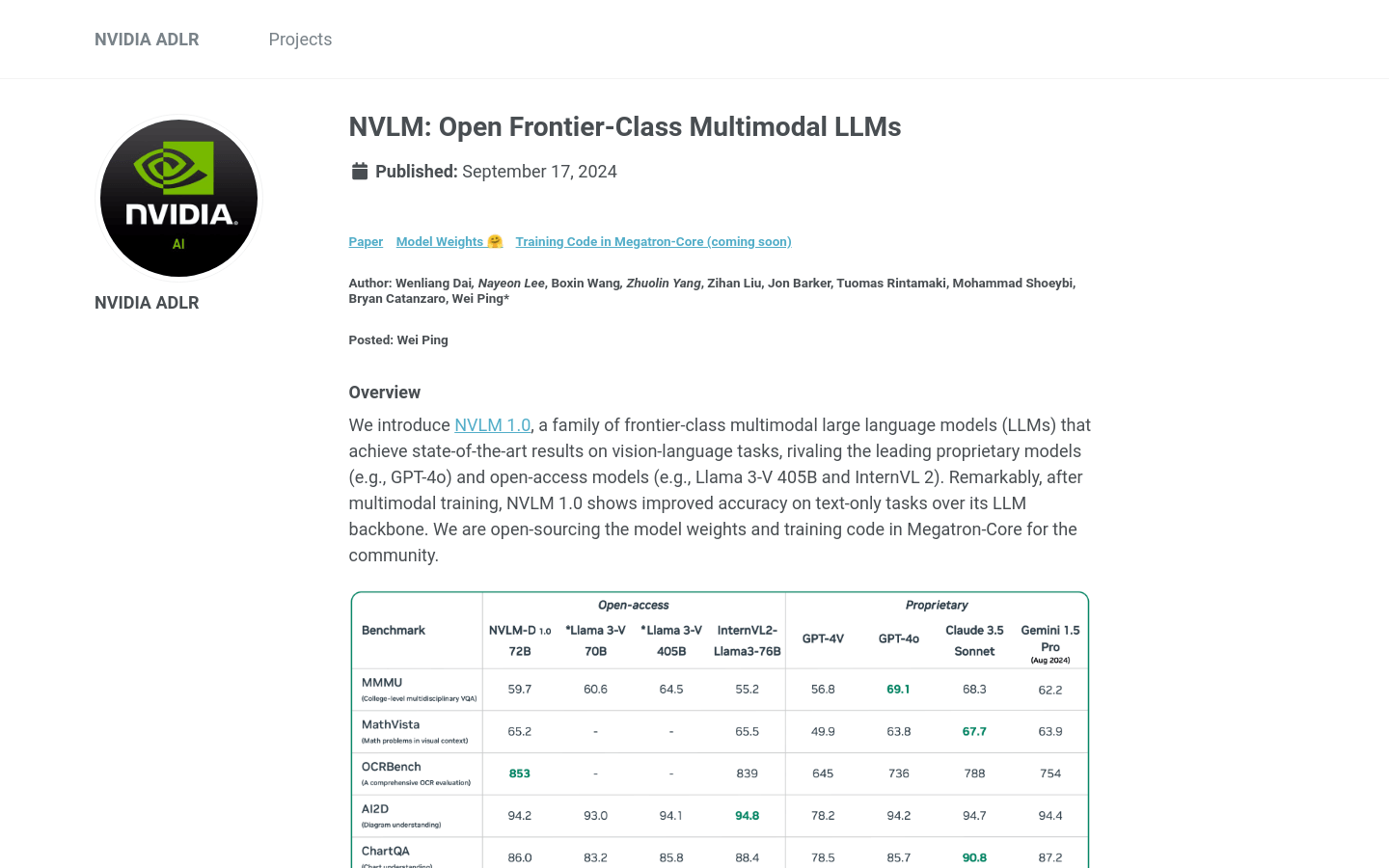
在视觉-语言任务上达到了业界领先水平。
多模态训练后,在纯文本任务上的准确性有所提高。
开源模型权重和训练代码,便于社区使用和研究。
在OCRBench和VQAv2等基准测试中取得了最高分。
在多模态任务中展现了出色的指令遵循能力和图像描述生成能力。
能够理解图像背后的幽默,执行OCR识别文本标签,并使用推理理解幽默的原因。
能够基于视觉信息执行数学推理和编码。
使用教程
访问NVIDIA ADLR的官方网站,下载NVLM 1.0的模型权重和训练代码。
阅读文档,了解模型的架构和使用方法。
根据需要,对模型进行微调,以适应特定的视觉-语言任务。
使用Megatron-Core训练代码对模型进行训练。
利用模型进行图像描述生成、OCR识别或数学推理等任务。
评估模型在特定任务上的性能,并根据结果进行优化。
将训练好的模型部署到实际应用中,如图像识别系统或自然语言处理工具。










