使用场景
使用Aria模型为教育视频自动生成字幕。
在医疗领域,利用Aria模型分析医疗影像和病例文档,以辅助诊断。
在安全监控领域,使用Aria模型分析视频流,以识别异常行为。
产品特色
支持多模态输入,包括文本、图像和视频。
能够处理长达64K的输入,适用于长视频和复杂文档的分析。
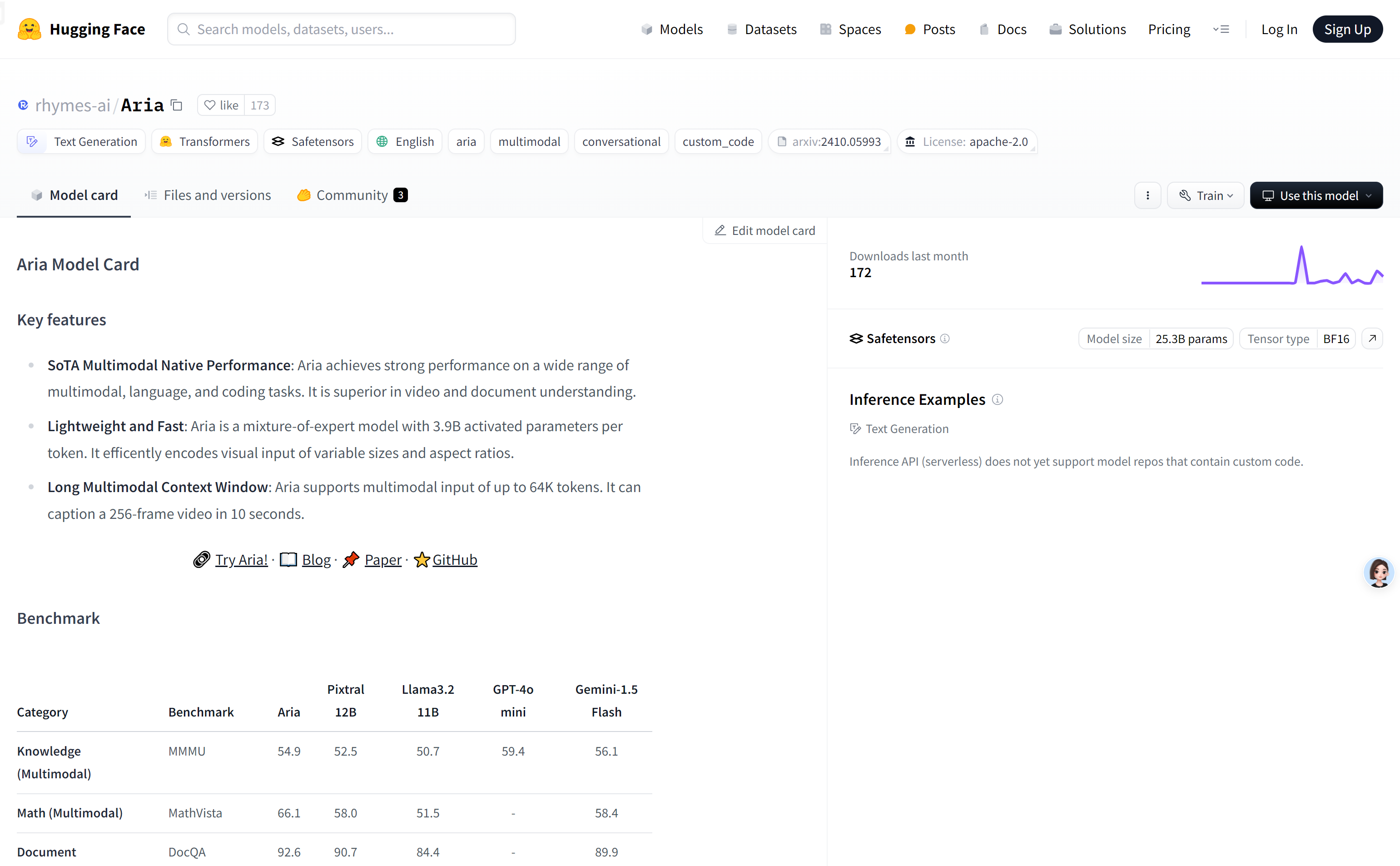
在多模态任务中表现出色,如视频理解、文档问答等。
支持多种编程语言和框架,易于集成和使用。
具有高效的编码能力,可以快速处理视觉输入。
开源模型,社区支持和持续更新。
使用教程
1. 安装必要的库和依赖,如transformers、torch等。
2. 使用pip命令安装Aria模型:`pip install transformers==4.45.0`。
3. 准备输入数据,包括文本、图像或视频。
4. 使用AutoModelForCausalLM和AutoProcessor加载Aria模型和处理器。
5. 将输入数据传递给模型进行处理,获取模型输出。
6. 根据需要对输出结果进行后处理,如解码、格式化等。
7. 分析和利用模型输出,如生成字幕、回答问题等。










