使用场景
企业使用FunASR进行会议录音的实时转写,快速生成会议纪要
在线教育平台利用FunASR将授课音频转换为文字资料,便于学生复习
媒体公司使用FunASR将采访录音转化为文字,提高编辑工作效率
产品特色
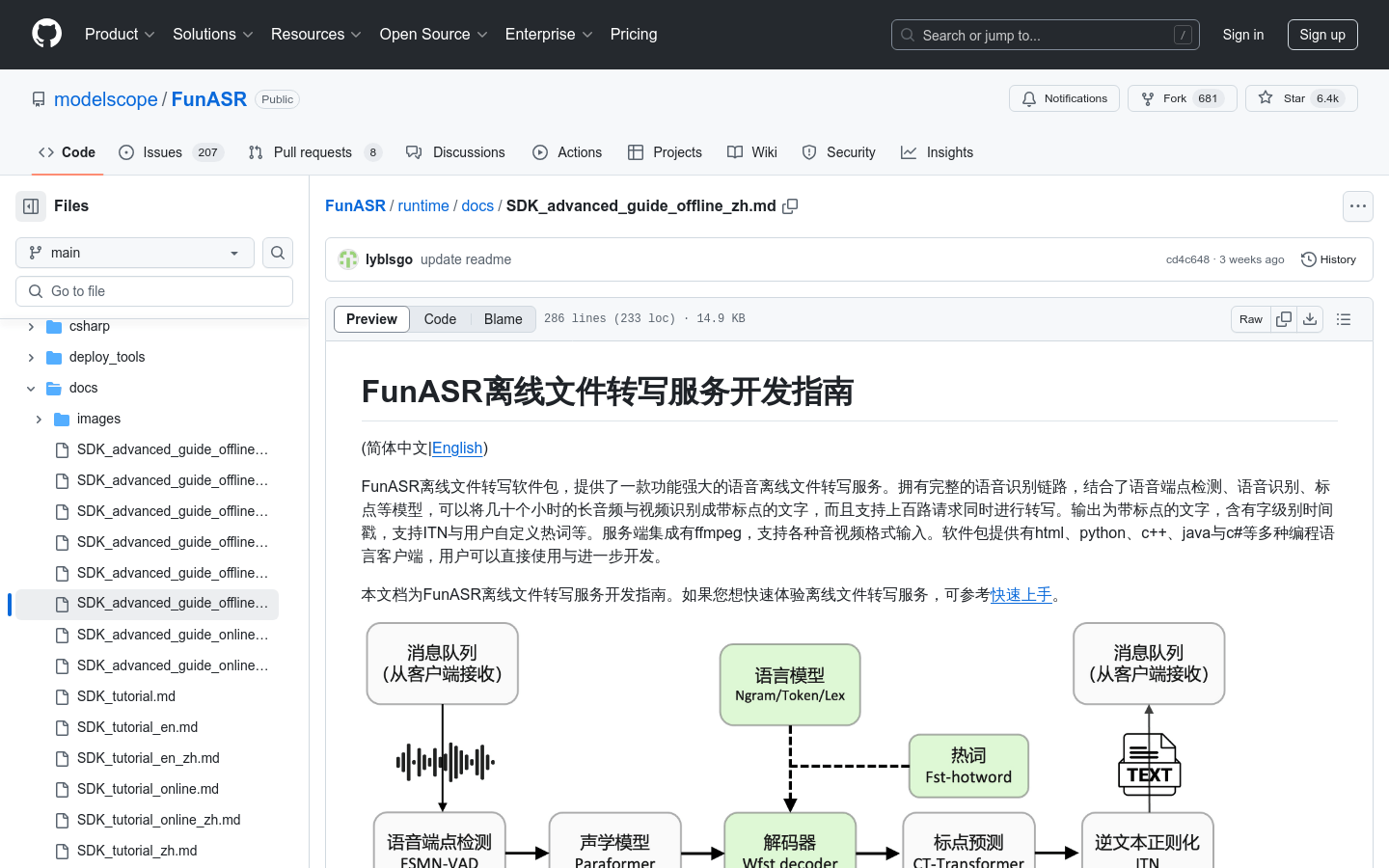
支持语音端点检测、语音识别、标点预测等完整语音识别链路
能够处理几十个小时的长音频与视频,转换成带标点的文字
支持上百路请求同时进行转写,适应高并发场景
服务端集成ffmpeg,支持多种音视频格式输入
提供html、python、c++、java与c#等多种编程语言客户端
支持字级别时间戳,方便文本与语音对齐
支持用户自定义热词,提高特定词汇的识别准确率
使用教程
1. 安装docker,如果已安装则跳过此步骤
2. 拉取FunASR软件包的docker镜像
3. 启动docker镜像,并映射相关资源目录
4. 在docker中启动funasr-wss-server服务程序
5. 下载客户端测试工具目录samples
6. 使用客户端进行音频文件的转写测试,例如使用Python客户端进行转写
7. 根据需要修改服务端或客户端代码,以适应特定业务需求










