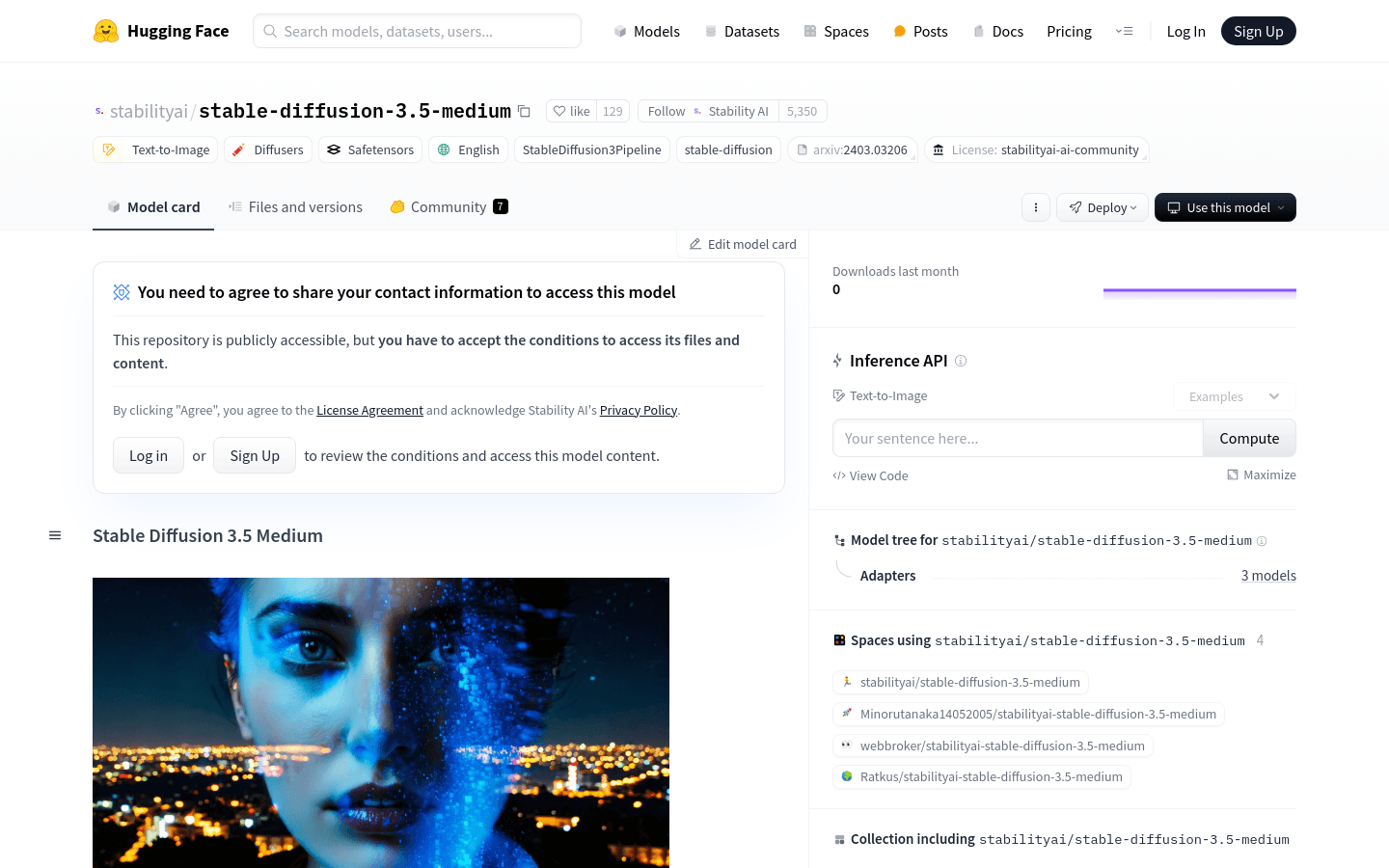
使用场景
艺术家使用Stable Diffusion 3.5 Medium根据文本提示创作数字艺术作品。
教育工作者利用该模型在课堂上展示如何从文本描述生成图像,增强学生对AI技术的理解。
研究人员使用模型分析生成图像的质量和一致性,以评估和改进生成模型的性能。
产品特色
• 基于文本提示生成高质量图像
• 改进的多分辨率图像生成能力
• 训练稳定性通过QK规范化技术提升
• 双注意力块增强图像一致性
• 支持长文本提示,但需注意token限制
• 与Diffusers库兼容,便于集成和部署
• 社区版许可适用于非商业用途和年收入少于100万美元的组织或个人
使用教程
1. 安装最新版本的Diffusers库:`pip install -U diffusers`
2. 导入必要的库并加载模型:`from diffusers import StableDiffusion3Pipeline`
3. 初始化模型管道并设置参数:`pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-medium", torch_dtype=torch.bfloat16)`
4. 将模型管道转移到GPU上以加速处理:`pipe = pipe.to("cuda")`
5. 使用文本提示生成图像:`image = pipe("A capybara holding a sign that reads Hello World", num_inference_steps=40, guidance_scale=4.5).images[0]`
6. 保存生成的图像:`image.save("capybara.png")`










