使用场景
电影制作中,使用SoundStorm快速生成背景音效和对话。
音乐制作人利用SoundStorm合成特定风格的音乐。
语音识别研究中,使用SoundStorm生成大量自然对话样本以训练模型。
产品特色
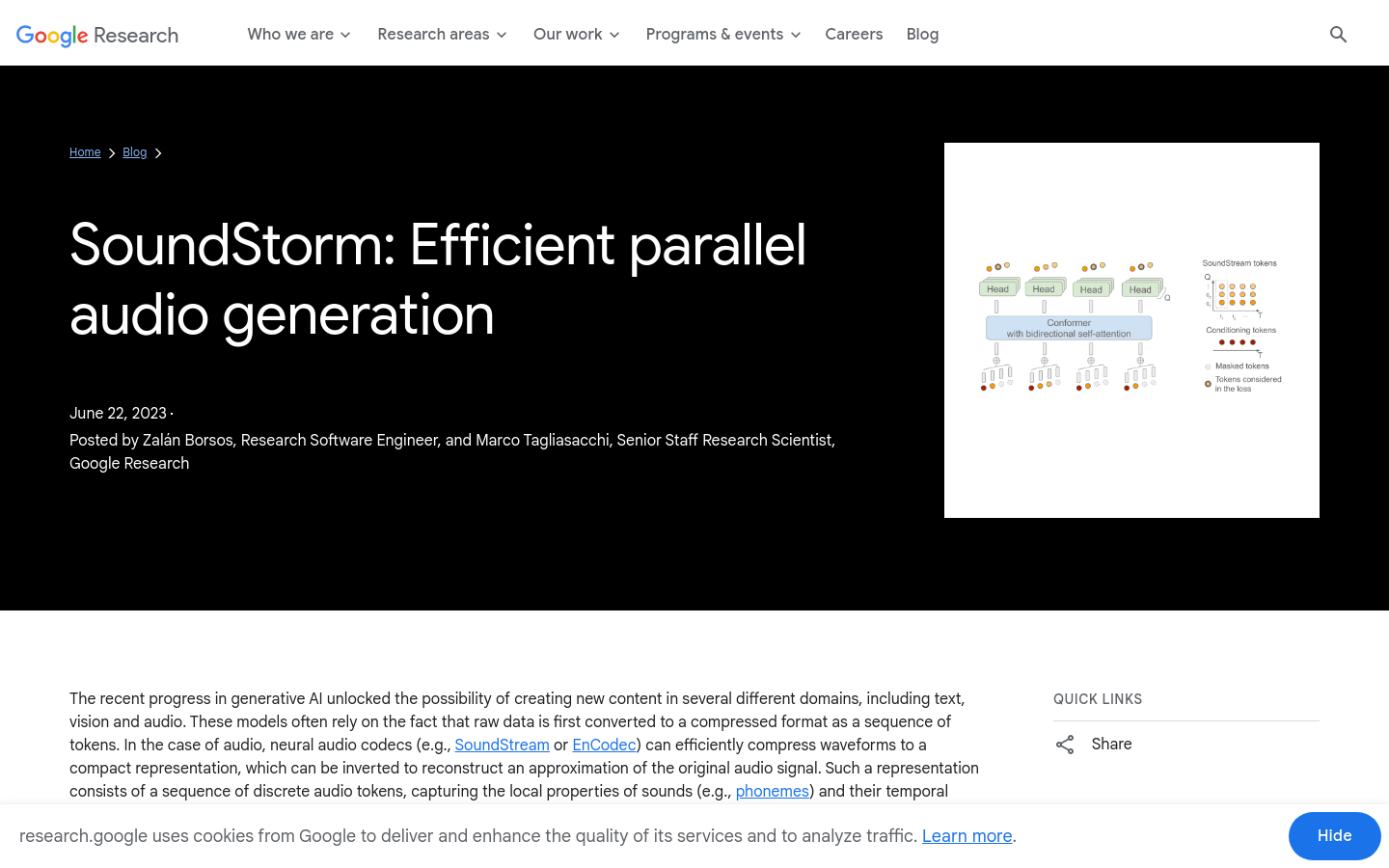
利用神经音频编解码器将音频波形压缩成紧凑的表示形式
基于Transformer的序列到序列模型进行音频生成
并行生成音频令牌,减少长序列的推理时间
保持与原始音频信号相同的音质和更高的语音及声学条件一致性
与文本到语义模型结合,控制生成的语音内容和说话者特征
支持长文本的语音合成和自然对话的生成
适用于音乐和音频内容的高效合成
使用教程
1. 准备文本或音频提示,作为音频生成的输入条件。
2. 使用SoundStorm模型将输入条件转换成语义令牌。
3. SoundStorm模型并行预测音频令牌,从粗糙到精细逐级生成。
4. 根据需要调整音频生成的参数,如语速、音调等。
5. SoundStorm输出生成的音频文件。
6. 将生成的音频文件用于所需的应用场景,如电影配音、音乐制作等。










