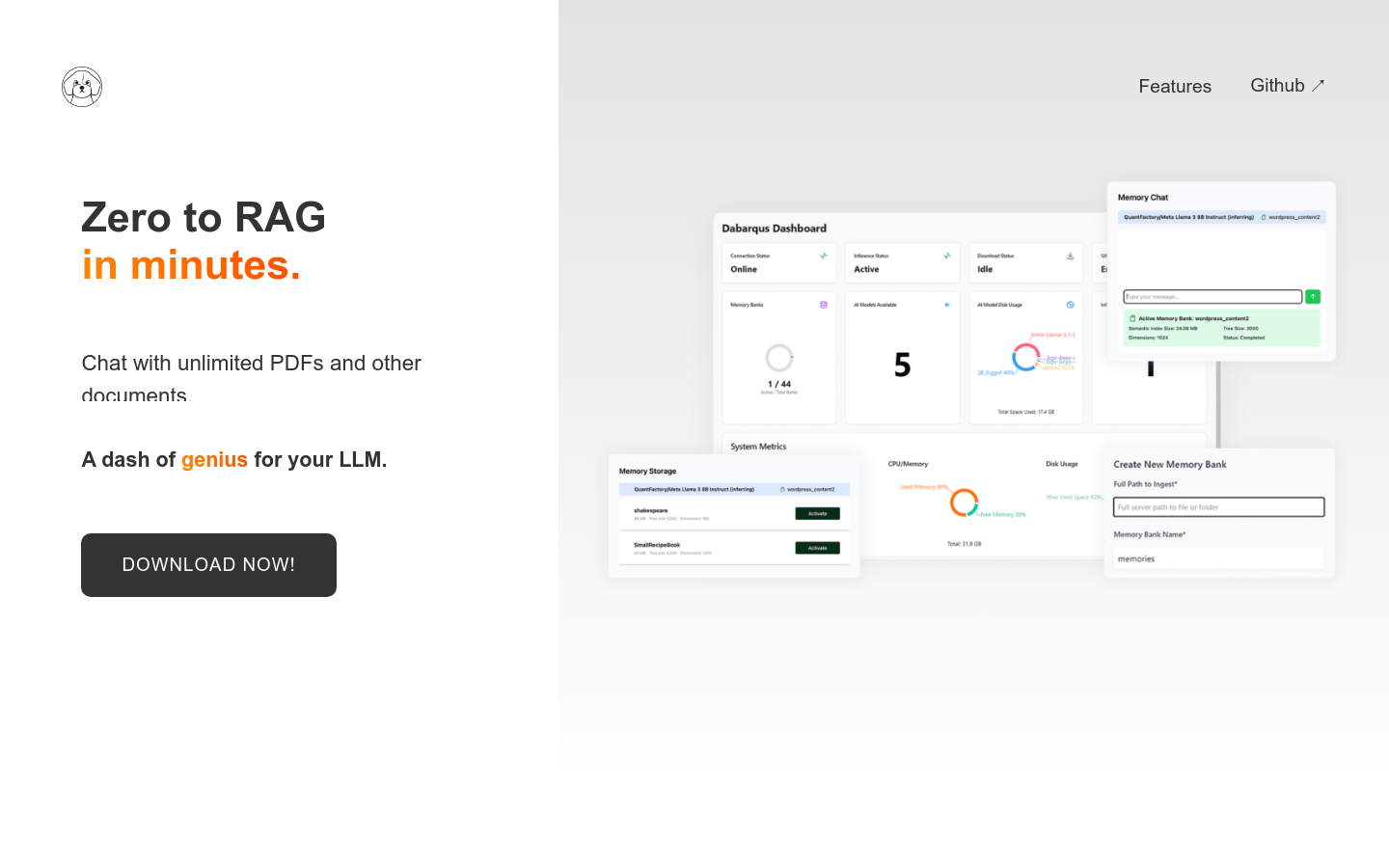
使用场景
开发者使用Dabarqus将企业内部的PDF文档集成到聊天机器人中,以提供更准确的信息检索。
数据科学家利用Dabarqus将研究数据存储在记忆库中,以便在机器学习模型中使用。
企业使用Dabarqus将客户服务记录整合到语言模型中,以提供更个性化的客户服务。
产品特色
支持多种数据源的集成,包括PDF、电子邮件和原始数据。
使用LLM风格的提示与记忆库进行交互,无需特殊查询语言。
提供REST API,方便与现有开发工具集成。
支持创建和管理多个语义索引(记忆库)。
提供Python和JavaScript的SDK,方便项目集成。
输出LLM兼容的输出,与ChatGPT、Ollama等LLM提供商无缝协作。
支持Linux、macOS和Windows平台。
使用教程
1. 下载并安装Dabarqus客户端。
2. 通过CLI或API将数据源(如PDF、电子邮件)存储到指定的记忆库中。
3. 使用LLM风格的提示对记忆库进行查询,以检索相关信息。
4. 利用Dabarqus的REST API和SDK将检索到的数据集成到现有的应用程序中。
5. 根据需要创建和管理多个语义索引(记忆库)。
6. 通过Dabarqus的输出与其他LLM提供商进行集成。
7. 在Linux、macOS和Windows平台上部署和使用Dabarqus。










