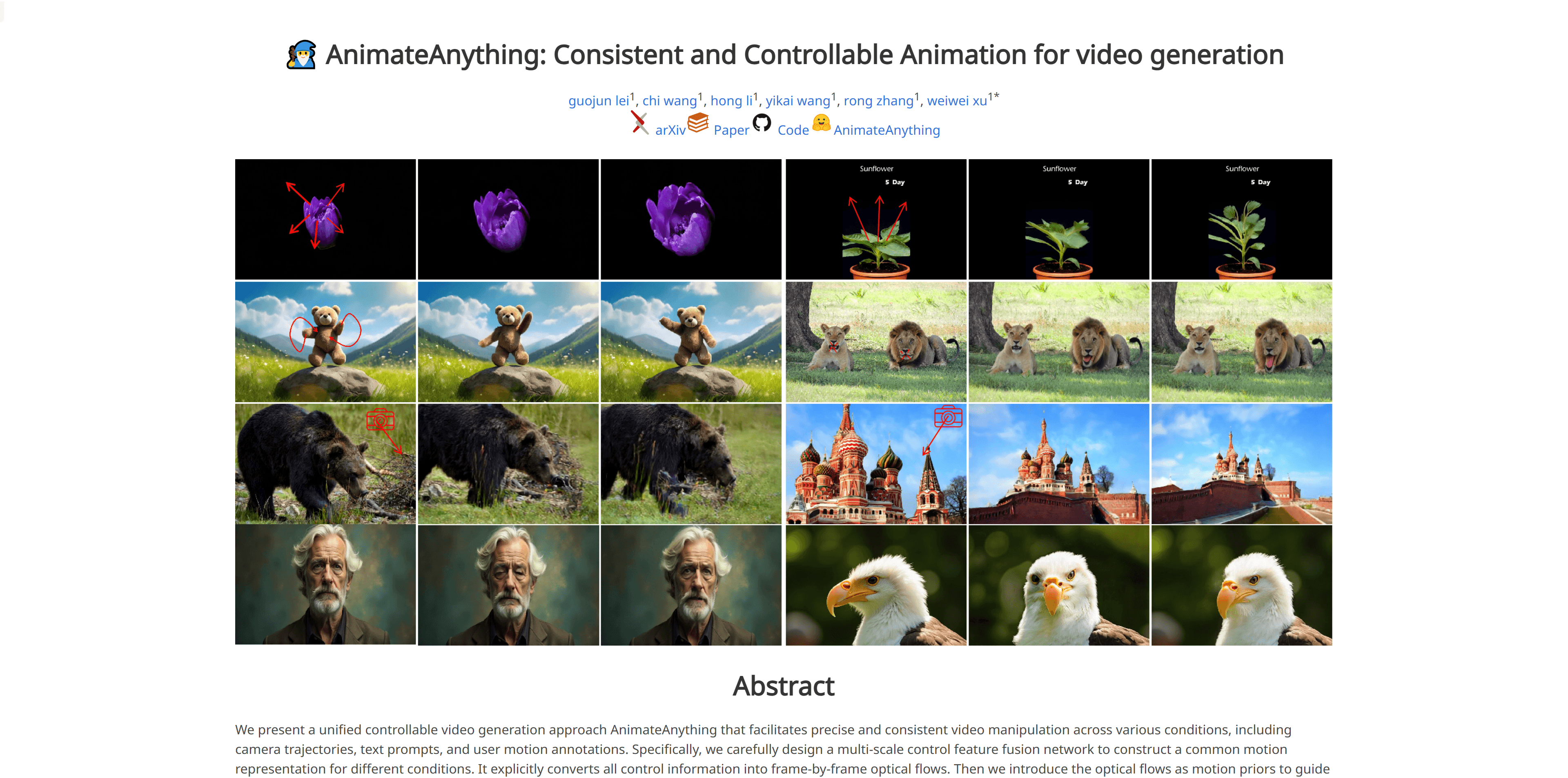
使用场景
- 使用AnimateAnything根据文本提示生成动画视频。
- 利用用户动作注释来驱动视频中角色的动作。
- 在不同的相机轨迹下生成一致性高的视频内容。
产品特色
- 多尺度控制特征融合网络:构建不同条件下的通用运动表示。
- 逐帧光流转换:将所有控制信息转换为光流,用于视频生成指导。
- 基于频率的稳定模块:减少大规模运动引起的闪烁问题,增强视频的时间连贯性。
- 精确和一致的视频操作:支持相机轨迹、文本提示和用户动作注释等条件下的视频操作。
- 优于现有最先进方法:实验结果表明AnimateAnything的性能优于其他方法。
- 统一的视频生成框架:由统一流生成和视频生成两部分组成。
- 可视化结果展示:提供不同场景下的视频生成效果对比。
使用教程
1. 访问AnimateAnything的官方网站。
2. 阅读首页上的产品介绍和功能概述。
3. 点击'Code'链接,访问GitHub页面,获取技术实现代码。
4. 根据GitHub页面上的说明文档,安装和配置所需的环境。
5. 下载并运行代码,开始使用AnimateAnything进行视频生成。
6. 根据需要,调整文本提示、相机轨迹和用户动作注释等控制信息。
7. 观察并评估生成的视频效果,根据需要进行调整以优化结果。










