使用场景
1. 数据中心利用d-Matrix进行大规模AI模型推理,提升数据处理速度和效率。
2. 云计算服务提供商通过d-Matrix为客户提供高性能AI推理服务,增强市场竞争力。
3. AI技术研发团队使用d-Matrix进行模型训练和推理测试,加速研发进程。
产品特色
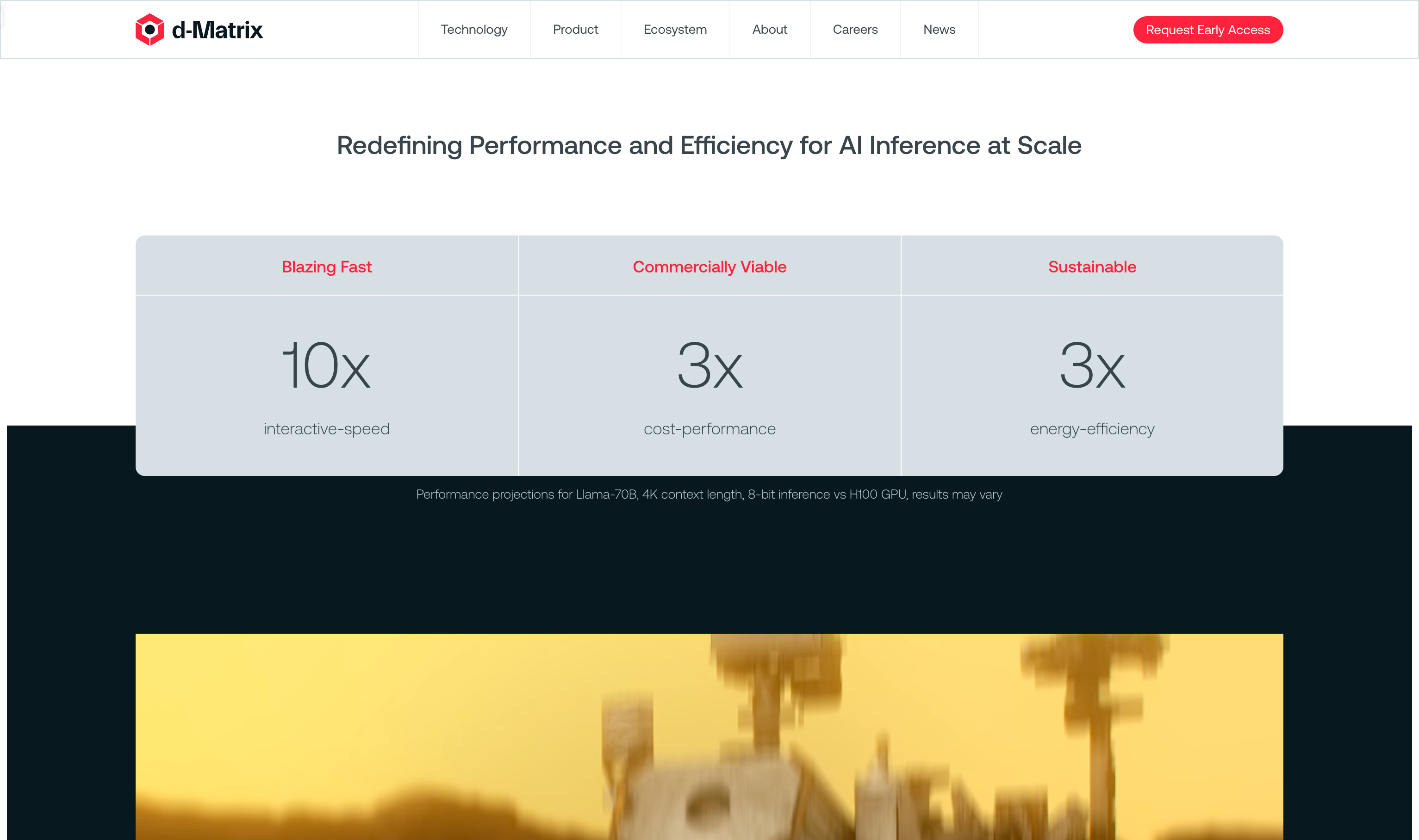
- 极速推理:单个服务器上Llama3 8B模型60,000 tokens/秒,1ms/tokens延迟。
- 高效推理:单个机架上Llama3 70B模型30,000 tokens/秒,2ms/tokens延迟。
- 交互速度:提供10倍于传统AI推理平台的交互速度。
- 成本效益:相较于传统方案,具有3倍的成本性能比。
- 能源效率:在能源效率上是传统方案的3倍。
- 可扩展性:能够随着模型大小的增加而扩展,适应不同规模和预算的公司需求。
- 硬件软件协同设计:通过硬件软件协同设计,优化Generative AI推理性能。
- 开源支持:推动开源,使Generative AI推理从不可持续变为可行。
使用教程
1. 访问d-Matrix官方网站了解产品详情。
2. 根据业务需求选择合适的d-Matrix产品配置方案。
3. 与d-Matrix联系,获取早期访问权限或购买服务。
4. 部署d-Matrix平台至数据中心,并进行必要的硬件和软件设置。
5. 根据d-Matrix提供的技术文档和支持,进行AI模型的推理测试。
6. 利用d-Matrix平台进行日常的AI推理任务,监控性能并优化配置。
7. 参与d-Matrix的开源社区,共享经验并获取技术支持。










