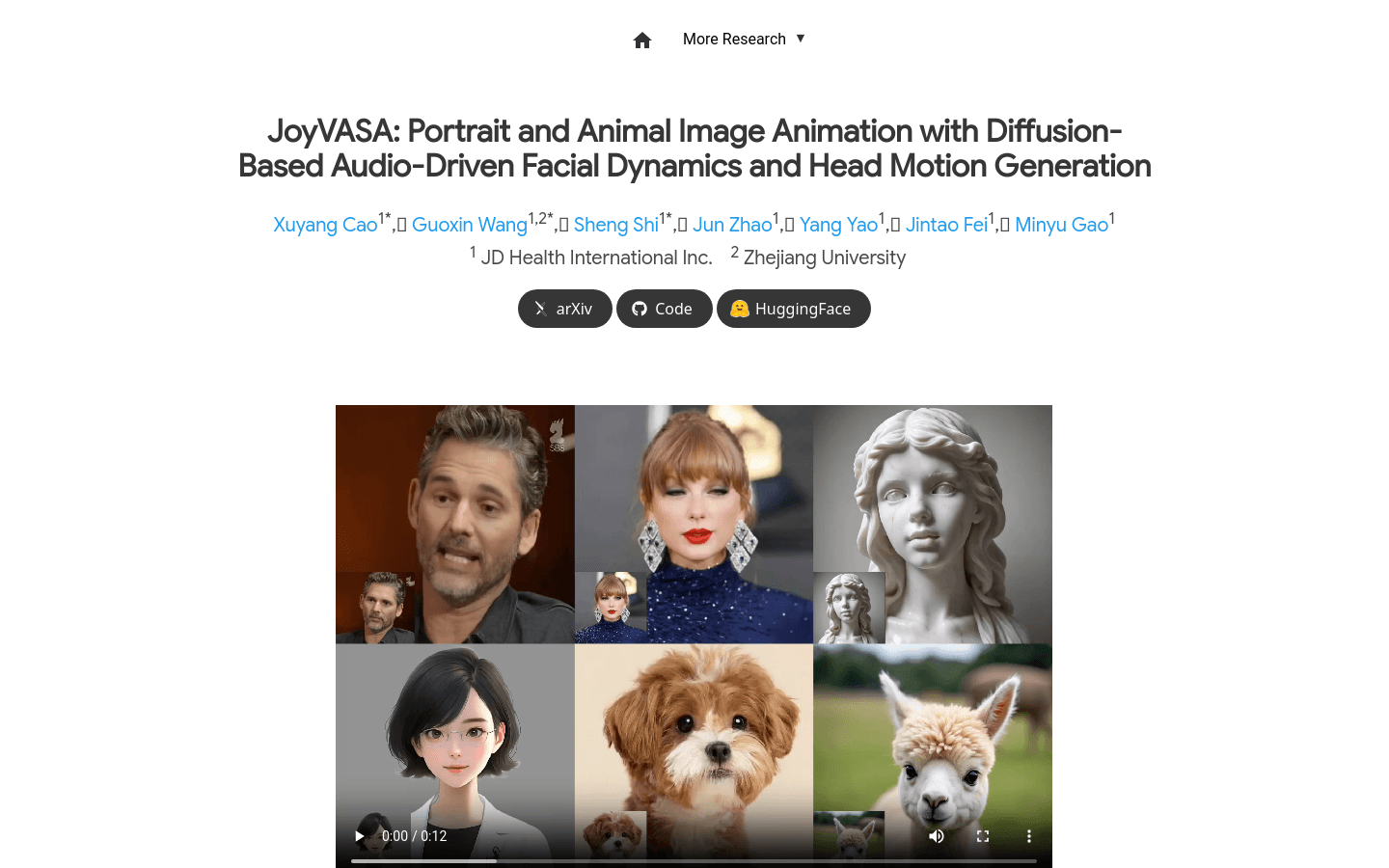
使用场景
视频制作者使用JoyVASA为电影制作逼真的音频驱动人像动画。
游戏开发者利用JoyVASA生成游戏中角色的动态面部表情和头部运动。
教育领域中,JoyVASA被用于创建多语言教学视频中的动态角色,以提高学习兴趣。
产品特色
分离动态面部表情与静态3D面部表示,以生成更长视频。
使用扩散变换器直接从音频提示生成运动序列,独立于角色身份。
第一阶段训练的生成器使用3D面部表示和生成的运动序列作为输入,渲染高质量动画。
支持动物面部动画,实现无缝扩展。
训练于混合数据集,包括中文和英文数据,支持多语言。
实验结果验证了方法的有效性。
使用教程
1. 提供一张参考图像,使用外观编码器提取3D面部外观特征和一系列学习到的3D关键点。
2. 对输入语音进行处理,使用wav2vec2编码器提取音频特征。
3. 使用扩散模型以滑动窗口方式采样音频驱动的运动序列。
4. 根据参考图像的3D关键点和采样的目标运动序列,计算目标关键点。
5. 根据源和目标关键点扭曲3D面部外观特征。
6. 渲染生成器根据扭曲的特征渲染最终输出视频。










