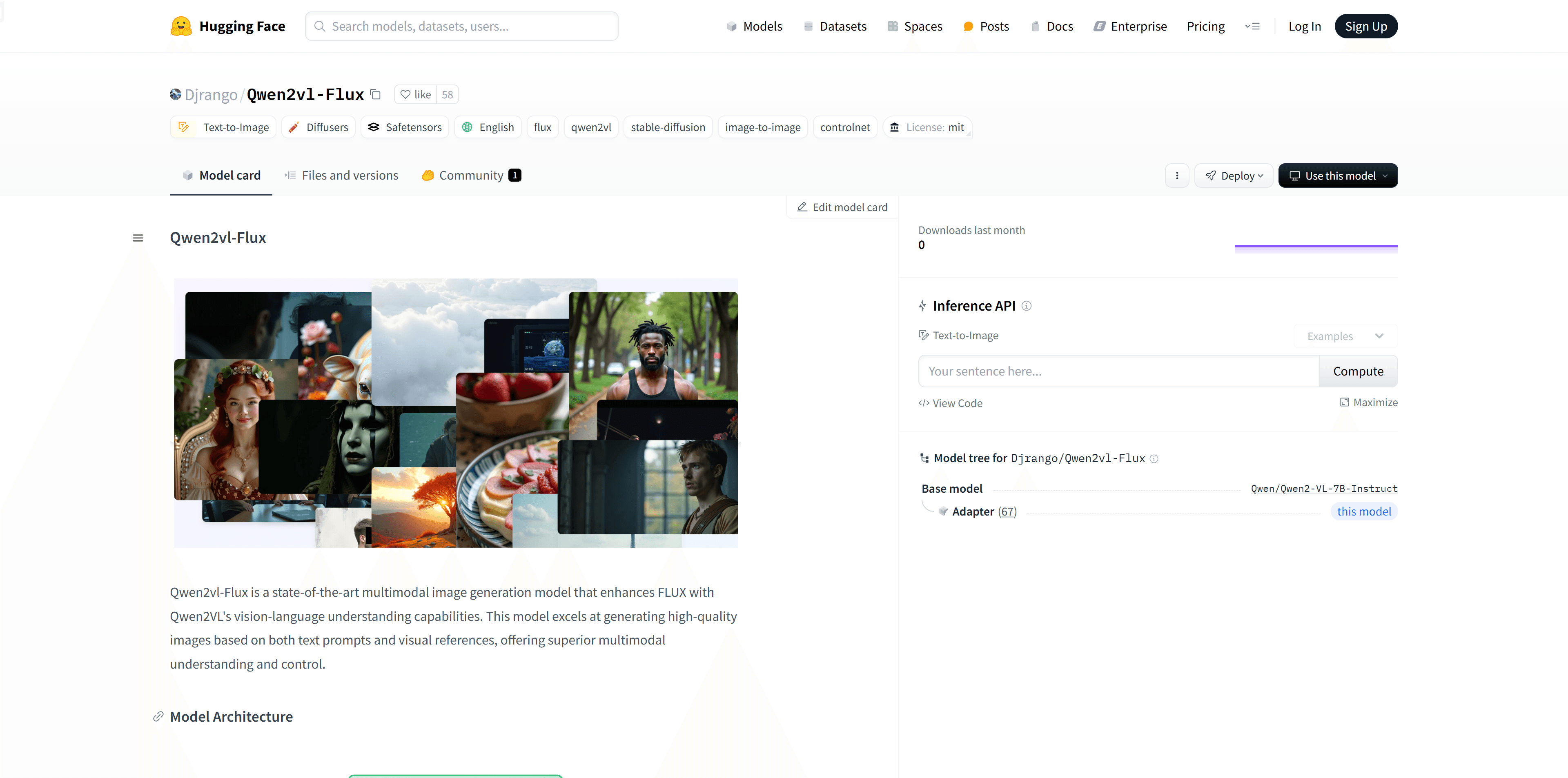
使用场景
创建在保持原始图像本质的同时产生多样化变体。
无缝混合多个图像,智能风格迁移。
通过文本提示控制图像生成。
应用细粒度风格控制的网格注意力。
产品特色
增强视觉语言理解:利用Qwen2VL实现更优的多模态理解。
多种生成模式:支持变体、图像到图像、修复和控制网引导的生成。
结构控制:集成深度估计和线条检测,提供精确的结构引导。
灵活的注意力机制:支持通过空间注意力控制的聚焦生成。
高分辨率输出:支持多种宽高比,最高可达1536x1024。
使用教程
1. 克隆GitHub仓库并安装依赖:使用git clone命令克隆Qwen2vl-Flux的GitHub仓库,并进入目录安装依赖。
2. 从Hugging Face下载模型检查点:使用huggingface_hub的snapshot_download函数下载Qwen2vl-Flux模型。
3. 初始化模型:在Python代码中导入FluxModel,并在指定设备上初始化模型。
4. 图像变体生成:使用模型的generate方法,输入原始图像和文本提示,选择'variation'模式生成图像变体。
5. 图像混合:输入源图像和参考图像,选择'img2img'模式,并设置去噪强度,生成混合图像。
6. 文本引导混合:输入图像和文本提示,选择'variation'模式,并设置引导比例,生成文本引导的图像混合。
7. 网格风格迁移:输入内容图像和风格图像,选择'controlnet'模式,并启用线条模式和深度模式,进行风格迁移。










