使用场景
在虚拟现实中,使用GaussianSpeech创建的3D人头化身可以作为用户在虚拟世界中的代表,提供更自然和真实的交互体验。
在电影制作中,GaussianSpeech可以用于生成逼真的面部动画,减少实际拍摄中对演员的需求,降低成本并提高效率。
在游戏开发中,GaussianSpeech可以用于创建NPC的面部动画,使游戏角色的表情更加丰富和真实,增强游戏的沉浸感。
产品特色
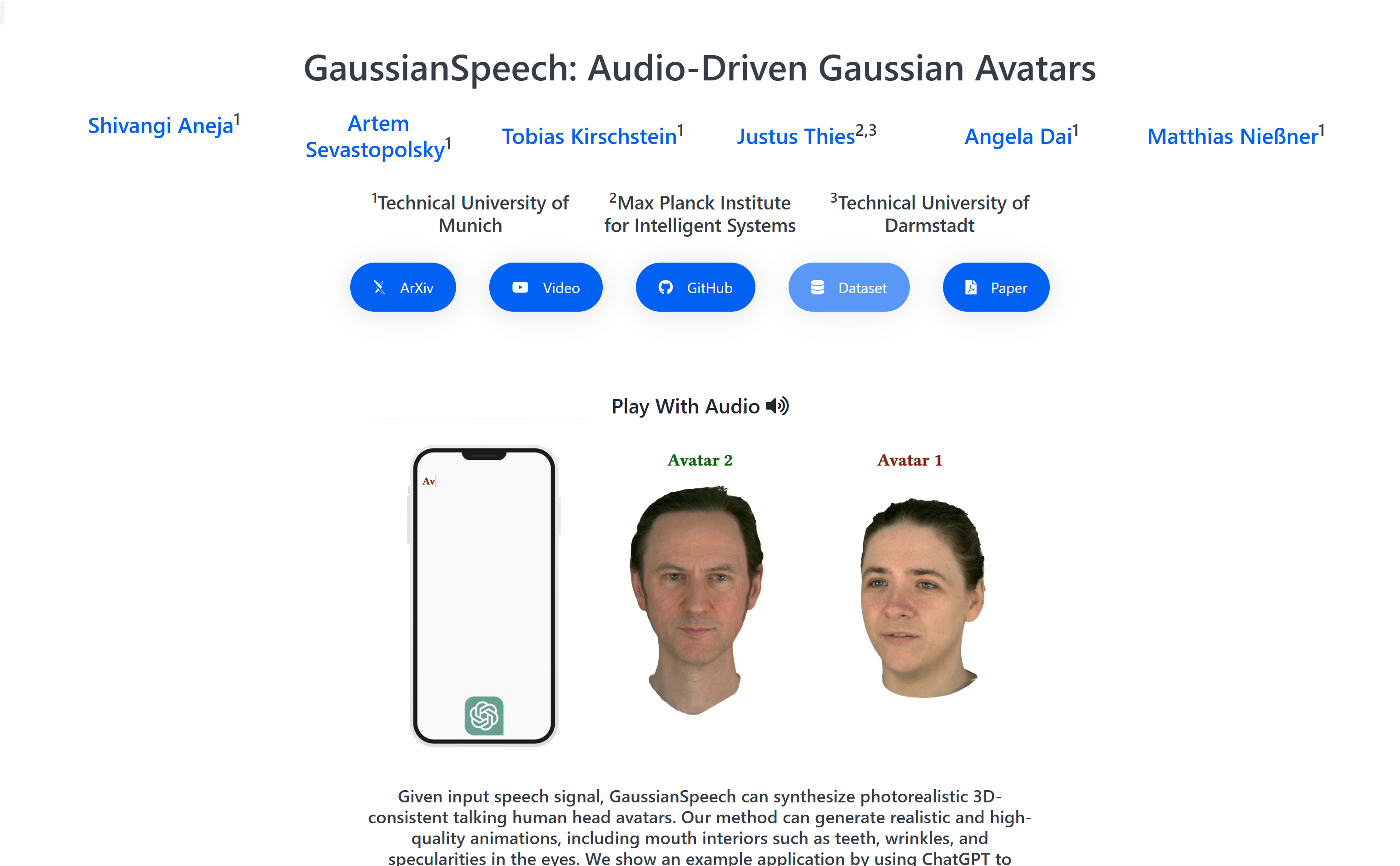
• 音频驱动:通过语音信号合成逼真的3D人头化身动画。
• 高保真度:生成包括牙齿、皱纹和眼睛中的光泽在内的细节动画。
• 实时渲染:以实时渲染速度呈现自然的视觉动态效果。
• 个性化表达:根据语音信号生成与表情相关的个性化颜色。
• 数据集支持:使用大规模多视角音频-视觉序列数据集进行训练。
• 音频特征提取:使用Wav2Vec 2.0编码器提取通用音频特征并映射到个性化唇部特征。
• 多模态融合:通过交叉注意力层将唇部-表情特征融合到解码器中。
• 3DGS Avatar表示:生成依赖于表情和视图的颜色,并应用皱纹和感知损失以提高照片真实感。
使用教程
1. 访问GaussianSpeech的GitHub页面,下载必要的代码和数据集。
2. 根据文档说明,设置开发环境并安装所需的依赖库。
3. 使用Wav2Vec 2.0编码器处理输入的语音信号,提取音频特征。
4. 利用Lip Transformer Encoder和Wrinkle Transformer Encoder从音频特征中提取唇部和皱纹特征。
5. 使用Expression Encoder合成FLAME表情,并通过Expression2Latent MLP将这些表情与唇部特征结合。
6. 将结合的特征输入到运动解码器中,预测FLAME顶点偏移。
7. 将预测的顶点偏移添加到模板网格中,生成规范空间中的顶点动画。
8. 在训练过程中,通过优化的3DGS化身和颜色MLP以及高斯潜在变量进一步细化动画,并通过重渲染损失进行优化。










