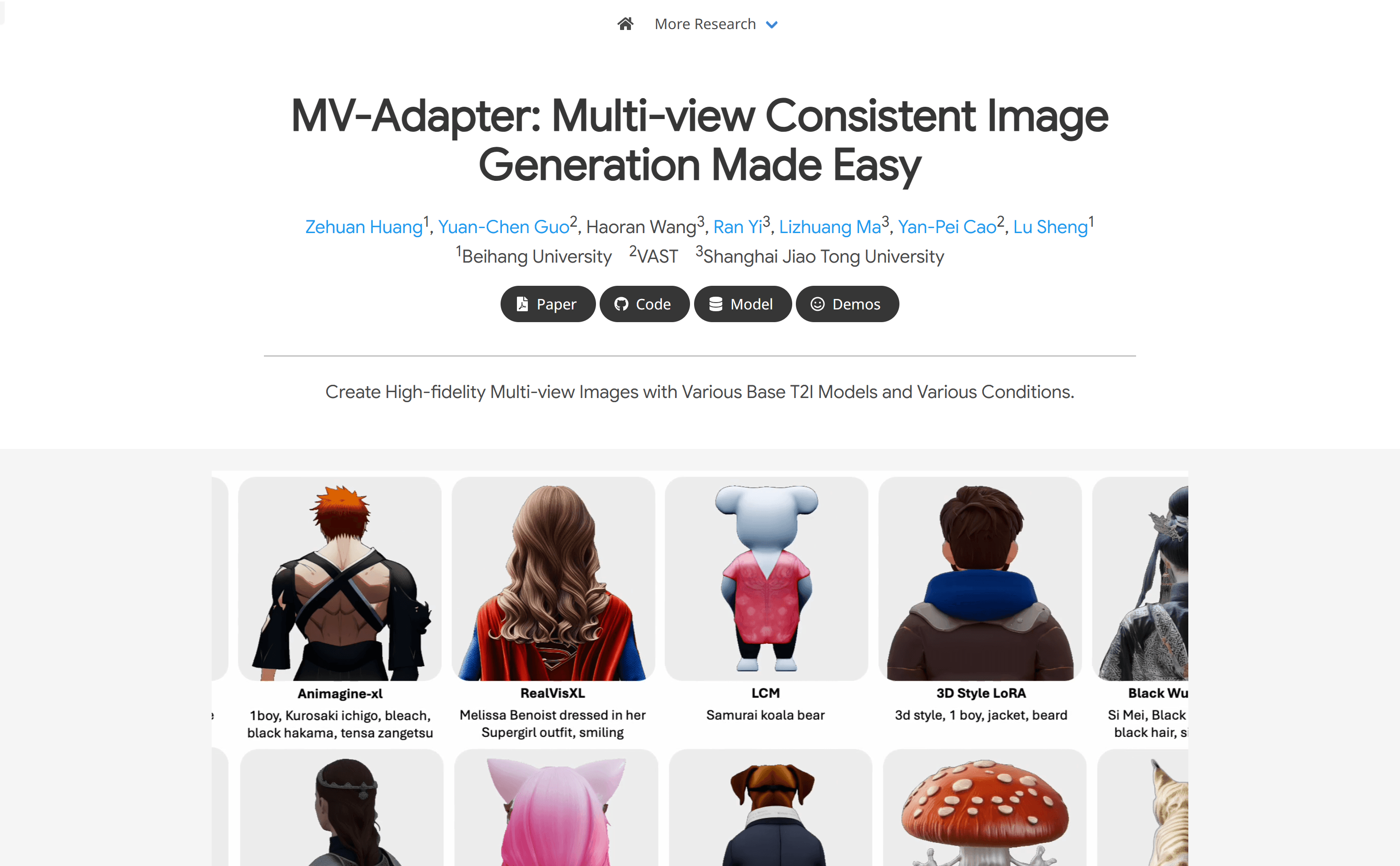
使用场景
案例一:研究人员使用MV-Adapter生成具有不同视角的3D模型图像,用于虚拟现实应用。
案例二:开发者利用MV-Adapter从单一图像生成多角度视图,用于创建更丰富的产品展示。
案例三:艺术家通过MV-Adapter将文本描述转换为从多个视角观察的一致性图像,用于创作新颖的艺术作品。
产品特色
• 适配器基础解决方案:MV-Adapter作为首个适配器基础的多视图图像生成解决方案,无需对预训练模型进行侵入性修改。
• 高效训练与知识保留:通过更新较少的参数,MV-Adapter能够在保持预训练模型先验知识的同时实现高效训练。
• 3D几何知识建模:引入复制的自注意力层和并行注意力架构,有效建模3D几何知识。
• 统一条件编码器:整合相机参数和几何信息,支持文本和图像条件的3D生成。
• 多视图一致性:能够生成在不同视图下保持一致性的高质量图像。
• 扩展性:MV-Adapter可以扩展到任意视图的生成,具有广泛的应用前景。
• 高分辨率生成:在Stable Diffusion XL上实现768分辨率的多视图生成。
使用教程
1. 访问MV-Adapter的GitHub页面,下载模型和代码。
2. 阅读文档,了解MV-Adapter的工作原理和配置要求。
3. 根据文档指导,设置环境并安装必要的依赖库。
4. 将下载的代码和模型文件放置在适当的目录中。
5. 运行代码,根据需要输入文本或图像条件,开始多视图图像生成。
6. 观察生成结果,根据需要调整参数以优化图像质量。
7. 将生成的多视图图像应用于进一步的研究或产品开发中。










