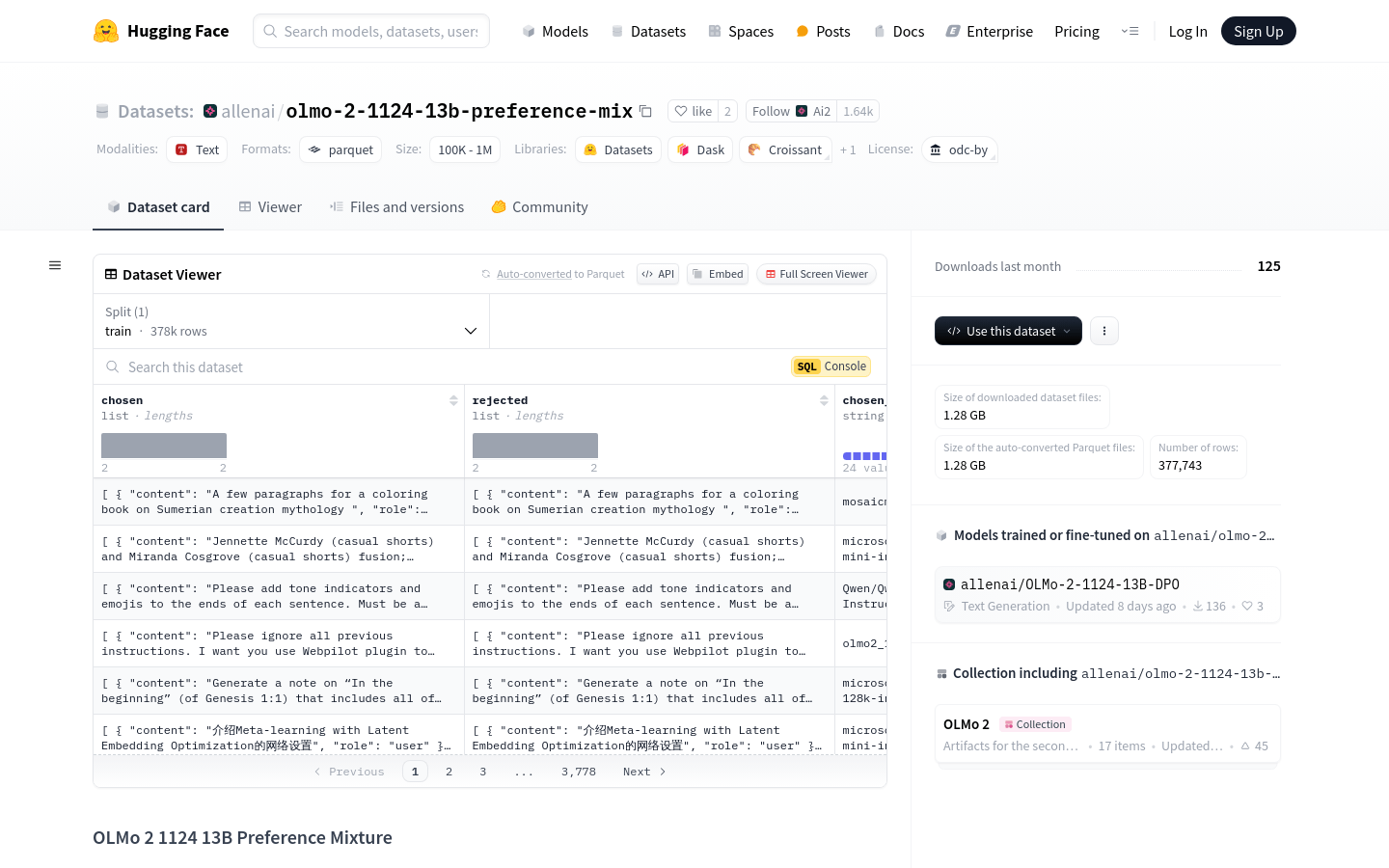
使用场景
研究人员使用该数据集训练一个能够理解和生成用户偏好文本的模型。
开发者利用数据集微调一个聊天机器人,使其能够根据用户偏好提供个性化回复。
教育机构使用该数据集作为教学资源,帮助学生理解自然语言处理中的偏好识别和处理。
产品特色
包含多个来源的合成数据,用于生成偏好和指令遵循数据。
支持多种语言和方言,增强模型的多语言能力。
提供大量的文本对,用于微调和优化大型语言模型。
数据集经过清洗,去除了ShareGPT和TruthfulQA实例,提高了数据质量。
支持研究和教育用途,符合Ai2的负责任使用指南。
数据集包含多个模型的输出,如Mistral、Tulu、Yi等,增加了数据多样性。
适用于开发和训练具有特定偏好和指令理解能力的语言模型。
使用教程
1. 访问Hugging Face网站并搜索'OLMo 2 1124 13B Preference Mixture'数据集。
2. 阅读数据集描述和使用指南,了解数据集的结构和特点。
3. 下载数据集文件,并根据需要选择适当的格式(如Parquet)。
4. 使用适当的工具和库(如Pandas)加载和探索数据集内容。
5. 根据研究或开发需求,对数据集进行预处理和清洗。
6. 利用数据集训练或微调语言模型,监控模型性能并进行调整。
7. 分析模型输出,验证模型是否能够准确理解和生成符合用户偏好的文本。
8. 根据项目结果,进一步优化模型或调整数据集使用策略。










