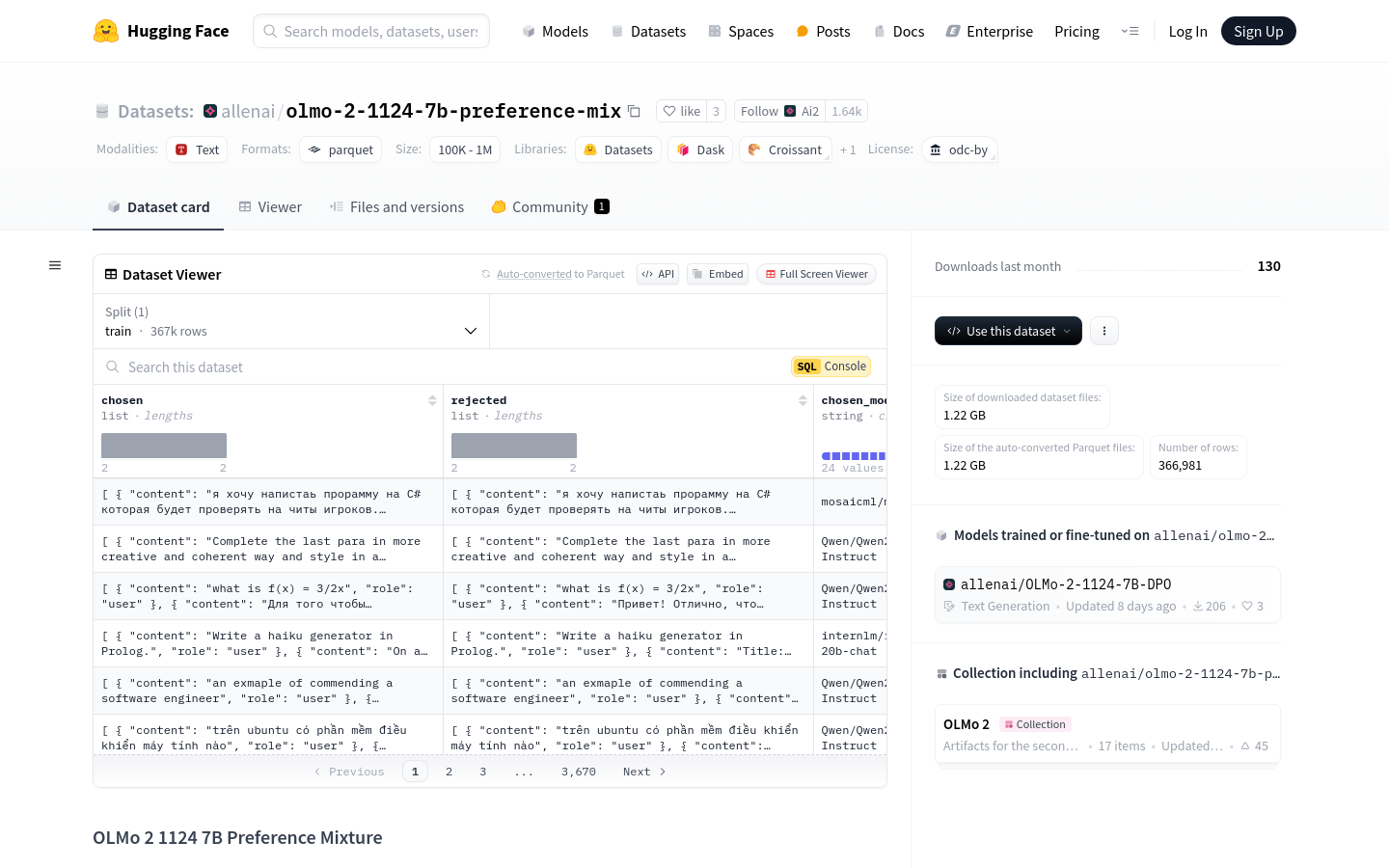
使用场景
研究人员使用该数据集来训练聊天机器人,以更好地理解用户的查询意图。
开发者利用数据集中的对话数据来优化语音助手的响应准确性。
教育工作者使用该数据集来教授学生如何构建和评估自然语言处理模型。
产品特色
包含多个来源的数据,用于构建全面的偏好学习模型
支持自然语言处理模型的训练和微调
适用于研究用户意图和偏好的混合
数据集包含366.7k个生成对,覆盖广泛的语言使用场景
适用于教育和研究领域,帮助理解语言模型的行为
数据集可用于开发聊天机器人和其他交互式应用
支持多种自然语言处理任务,如文本分类、情感分析等
数据集遵循ODC-BY许可,适用于研究和教育用途
使用教程
1. 访问 Hugging Face 数据集页面并下载所需的数据集文件。
2. 根据项目需求,选择合适的模型和工具来处理数据集。
3. 使用数据集训练或微调自然语言处理模型。
4. 分析模型输出,调整参数以优化性能。
5. 将训练好的模型应用于实际问题,如聊天机器人开发或文本分析。
6. 根据需要,对数据集进行进一步的清洗和预处理。
7. 记录实验结果,并根据反馈迭代改进模型。










