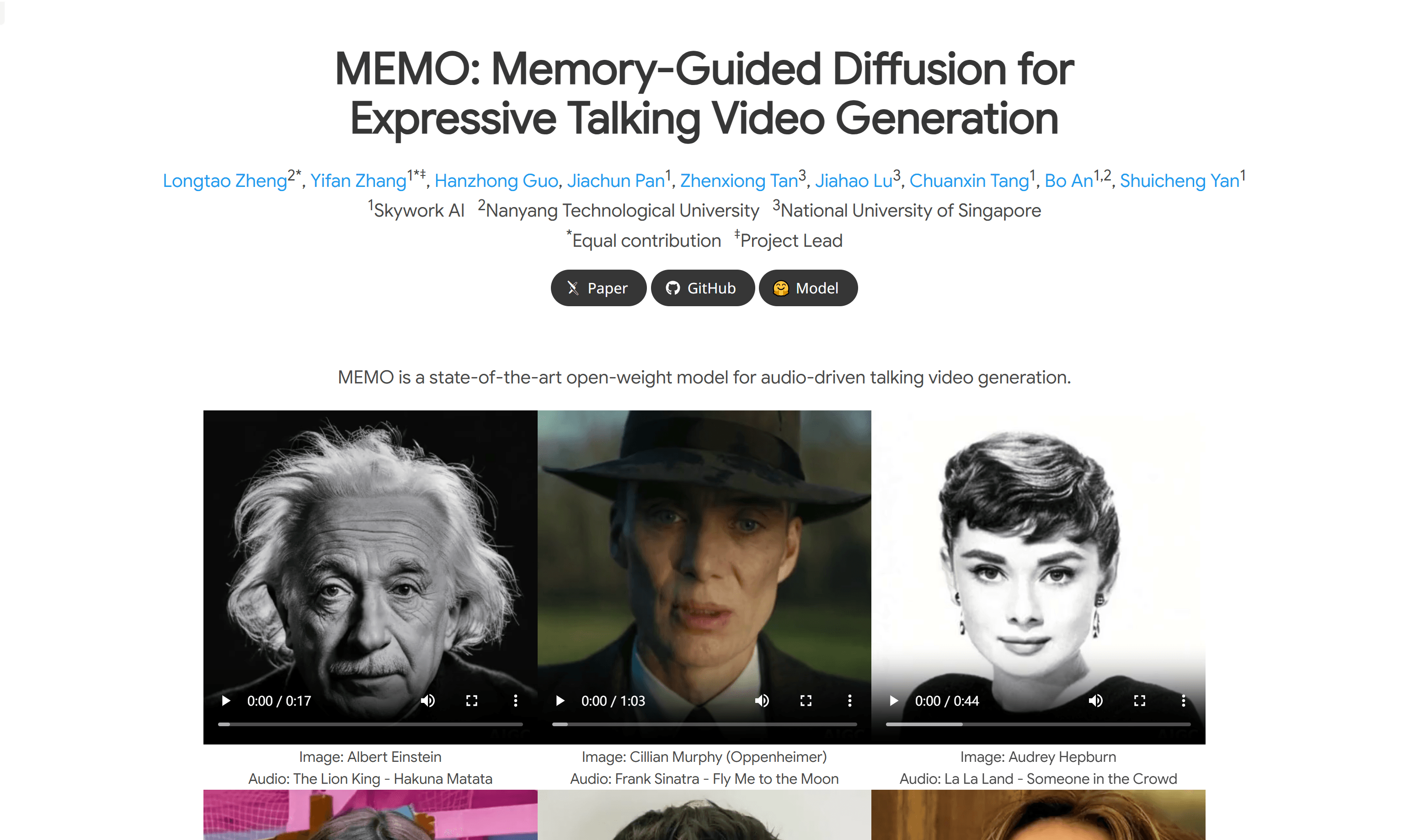
使用场景
使用爱因斯坦的肖像和《狮子王》的音频生成说话视频。
将奥黛丽·赫本的肖像与《爱乐之城》的音频结合起来,生成富有表情的视频。
使用Jang Won-young的肖像和ROSÉ & Bruno Mars的音频生成唱歌视频。
产品特色
记忆引导的时间模块:通过开发记忆状态来存储更长时间过去上下文的信息,以指导时间建模,增强长期身份一致性和运动平滑性。
情感感知的音频模块:用多模态注意力替换传统的交叉注意力,增强音频-视频交互,并从音频中检测情感以细化面部表情。
支持多种图像风格:包括肖像、雕塑、数字艺术和动画。
支持多种音频类型:包括语音、唱歌和说唱。
支持多语言:如英语、普通话、西班牙语、日语、韩语和粤语。
表达性视频生成:能够生成富有表情的视频或在视频中偏移情感。
支持不同头部姿势:能够生成不同头部姿势的说话视频。
长视频生成:能够生成持续时间较长的说话视频,减少伪影和错误累积。
使用教程
1. 访问MEMO的GitHub页面,下载并安装必要的模型和代码。
2. 准备所需的音频文件和参考图像,确保它们符合模型的输入要求。
3. 使用MEMO模型将音频和图像输入到系统中,开始生成说话视频。
4. 根据需要调整模型参数,以优化视频的音频-唇形同步、身份一致性和表情情感对齐。
5. 生成的视频可以进一步编辑或直接用于各种应用,如社交媒体、广告或教育材料。
6. 确保在使用MEMO生成的内容时遵守相关的法律、文化规范和伦理标准,尊重所有相关方的权利。










