使用场景
研究人员使用该数据集训练一个能够理解和生成多种语言文本的AI模型。
开发者利用数据集中的样本来优化他们的聊天机器人,使其能够更好地服务于多语言用户。
教育机构使用该数据集作为教材,教授学生如何使用和分析大规模语言数据。
产品特色
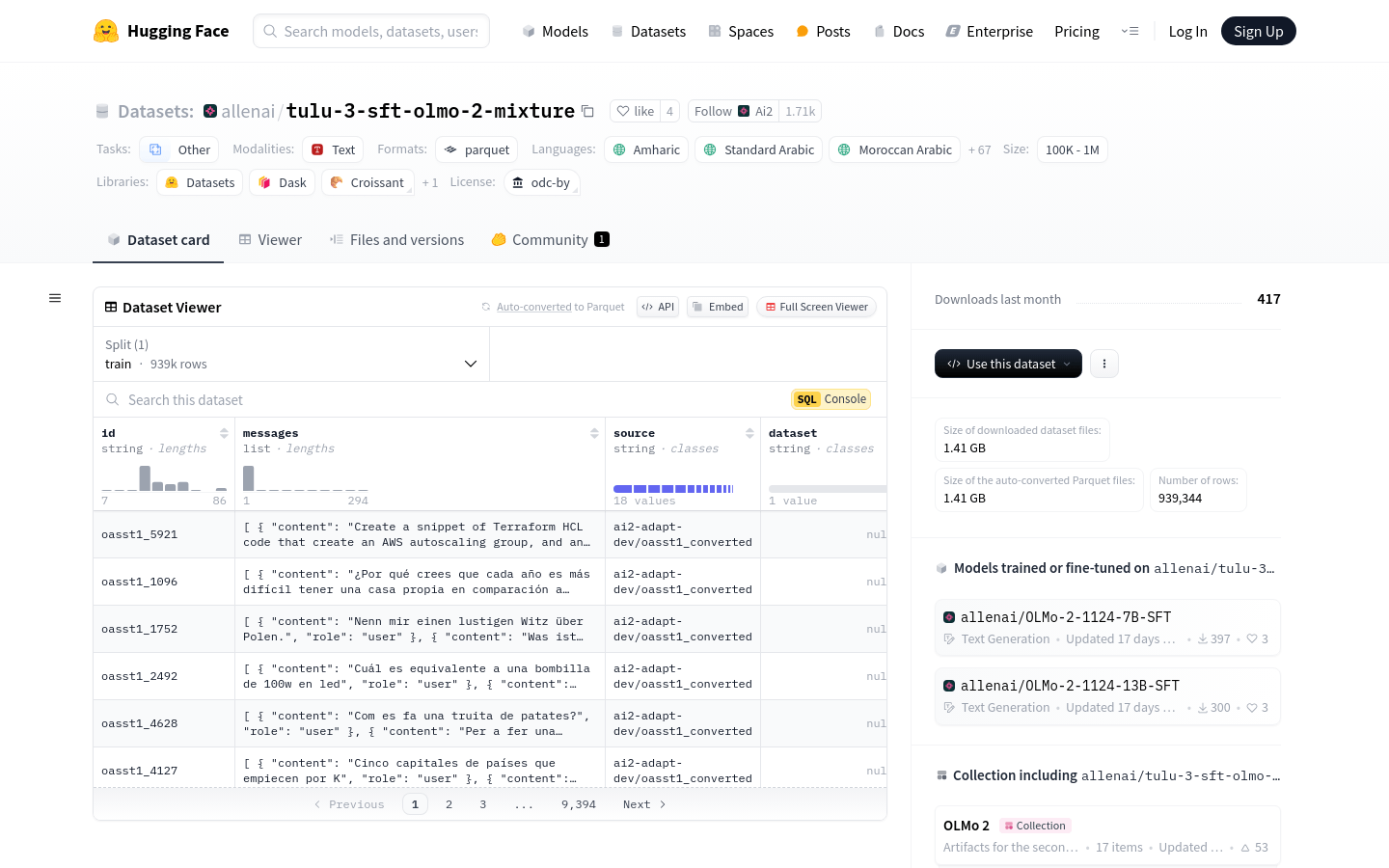
包含939,344个样本,覆盖多种语言和任务。
数据集来源于多个不同的数据集,如CoCoNot、FLAN v2、No Robots等。
适用于训练和微调语言模型,特别是在多语言环境下。
数据集结构包含id、messages、source等标准指令调整数据点。
支持研究和教育用途,符合Ai2的负责任使用指南。
包含输出数据,这些数据由第三方模型生成,受其单独的条款管辖。
数据集在Hugging Face平台上可被直接访问和使用。
使用教程
1. 访问Hugging Face平台并搜索allenai/tulu-3-sft-olmo-2-mixture数据集。
2. 阅读数据集的描述和使用许可,确保符合研究或教育目的。
3. 下载数据集,根据需要选择全部或部分数据。
4. 使用数据集训练或微调语言模型,观察模型在不同语言任务上的表现。
5. 分析模型输出,根据结果调整模型参数以优化性能。
6. 在教育或研究中应用模型,解决实际问题或提出新的研究假设。
7. 根据Ai2的负责任使用指南,合理使用和引用数据集。










