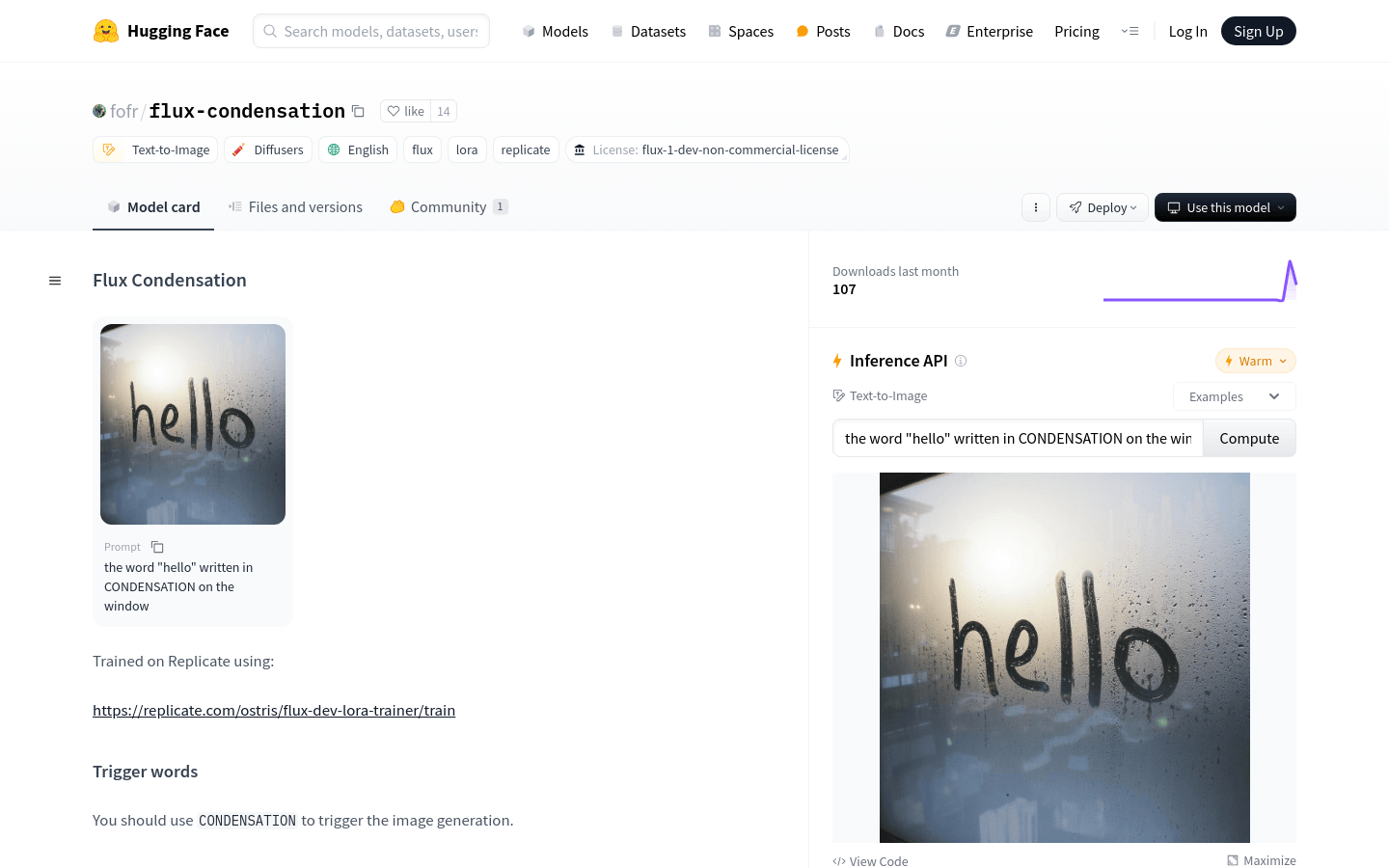
使用场景
设计师使用该模型根据设计概念快速生成设计草图。
艺术家利用模型创作数字艺术作品,探索新的艺术表现形式。
内容创作者为博客文章生成吸引人的封面图像,提高文章点击率。
产品特色
- 支持文本到图像的生成:用户只需输入文本提示,模型即可生成相应的图像。
- 使用LoRAs技术:通过微调模型的特定部分来改善性能,而不需要重新训练整个模型。
- 集成Diffusers库:方便用户快速部署和使用模型,支持在多种设备上运行。
- 支持CUDA加速:在支持CUDA的设备上,模型可以利用GPU加速图像生成过程。
- 非商业性质的许可证:适用于非商业用途,满足个人和学术研究的需求。
- 社区支持:模型在Hugging Face社区中拥有讨论板块,用户可以交流使用经验和反馈问题。
- 持续更新和维护:模型会根据最新的研究成果进行更新,保持技术的先进性。
使用教程
1. 安装Diffusers库和PyTorch框架。
2. 从Hugging Face模型库中加载预训练的模型和LoRAs权重。
3. 使用模型提供的API输入文本提示。
4. 模型将根据文本提示生成图像,并返回图像对象。
5. 将生成的图像保存到本地或直接在应用中展示。
6. 根据需要调整文本提示,以获得不同的图像结果。
7. 参与社区讨论,分享使用经验和反馈问题。










