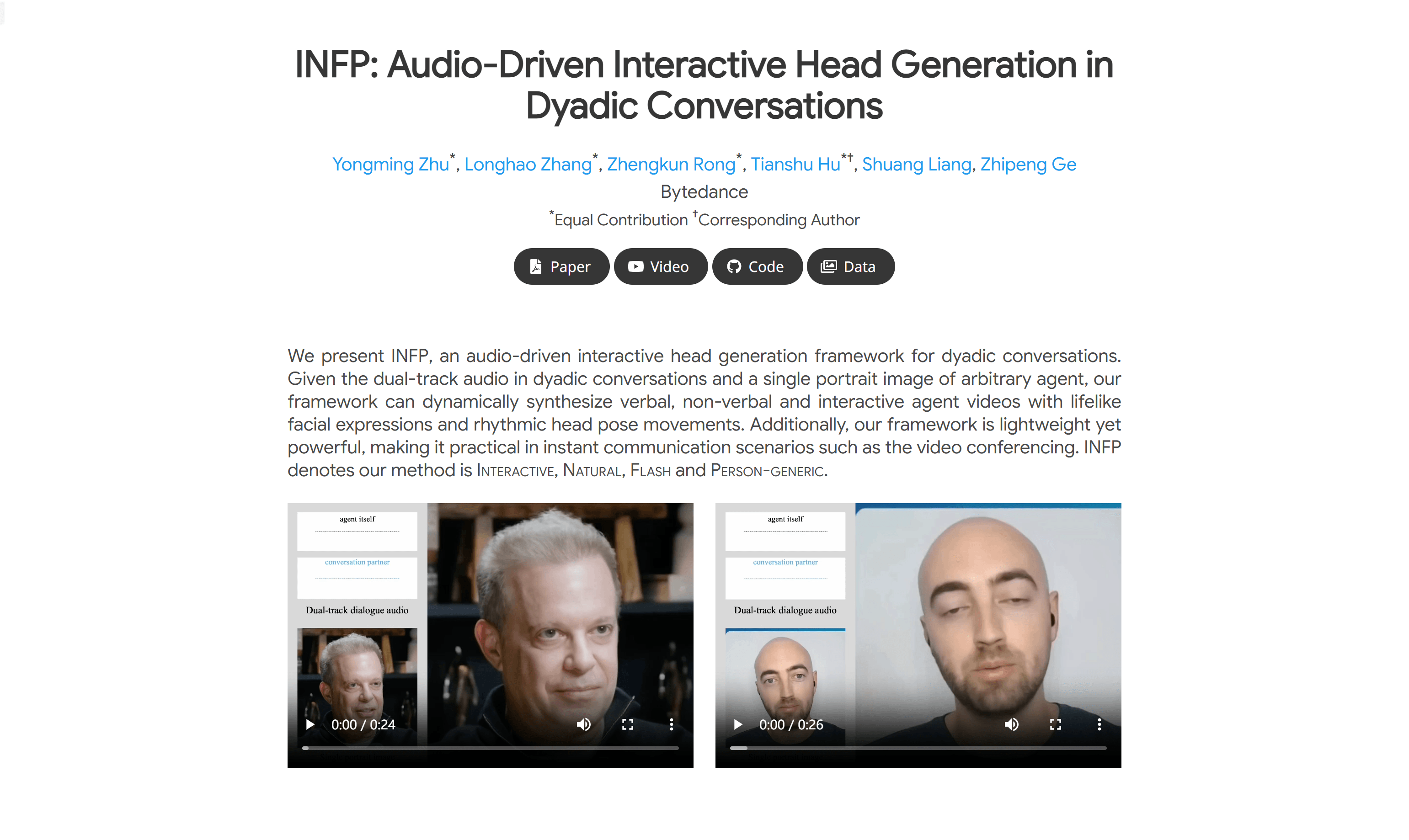
使用场景
视频会议中使用INFP生成的虚拟代理进行远程沟通。
在线教育中,教师使用INFP生成的虚拟形象进行授课。
客户服务中,使用INFP生成的虚拟客服代表与客户进行交互。
产品特色
- 动态合成言语、非言语和交互式代理视频:根据输入的双人音频和单人肖像图像,INFP能够动态合成具有逼真面部表情和头部动作的视频。
- 轻量而强大:INFP框架轻量,适合即时通讯场景,如视频会议。
- 交互式和自然:INFP能够自然地适应各种对话状态,无需手动切换角色。
- 快速推理速度:INFP在Nvidia Tesla A10上的速度超过40 fps,支持实时代理间通讯。
- 高唇同步精度:INFP生成的视频具有高唇同步精度,表达丰富的面部表情和节奏性头部姿态动作。
- 支持多种语言和歌唱:INFP能够支持不同语言和歌唱的头部生成。
- 高保真和自然面部行为:INFP生成的视频具有高保真度和自然面部行为,以及多样化的头部动作。
使用教程
1. 准备双人对话的双轨音频和一个代理的单人肖像图像。
2. 访问INFP的官方网站并下载相应的代码和数据集。
3. 根据INFP的文档说明,设置好环境并安装必要的依赖。
4. 将准备好的音频和图像输入到INFP框架中。
5. INFP框架将根据输入的音频动态生成交互式头部视频。
6. 观察生成的视频,检查视频的逼真度和交互性是否满足需求。
7. 如有需要,调整INFP的参数以优化视频生成效果。
8. 将生成的视频应用于实际的即时通讯场景中。










