使用场景
视频内容创作者可以使用该模型生成高质量的视频内容。
视频分析专家可以利用该模型进行视频内容的分析和处理。
教育领域中,教师可以使用该模型来创建教育视频,提高教学效果。
产品特色
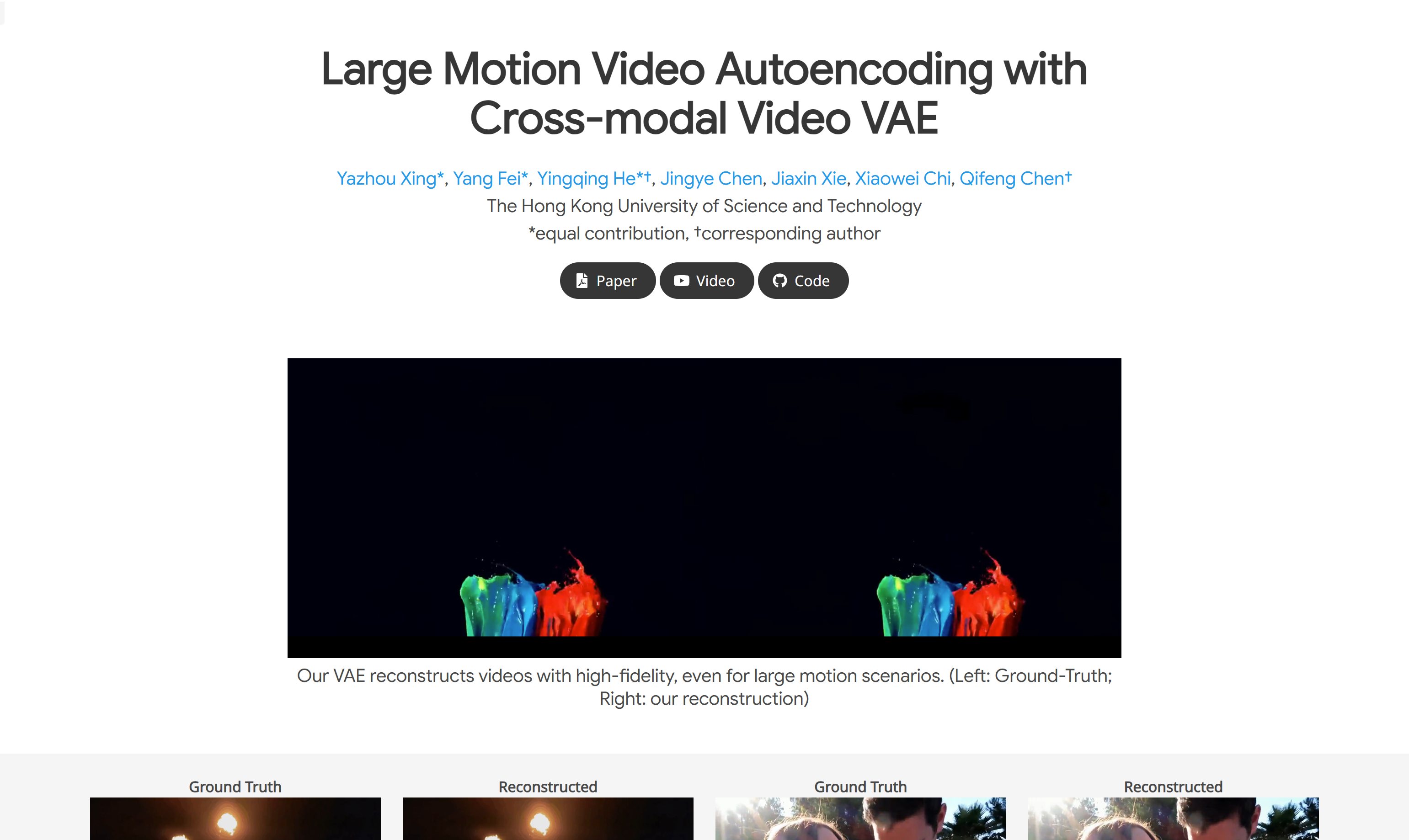
- 高保真视频编码:即使在大运动场景下也能保持视频质量。
- 时间感知的空间压缩:更好地编码和解码空间信息,减少运动模糊和细节失真。
- 轻量级运动压缩模型:进一步实现时间压缩,提高压缩效率。
- 文本指导:利用文本到视频数据集中的文本信息,提高重建质量。
- 联合训练:在图像和视频上进行训练,增强模型的通用性和重建质量。
- 细节保留和时间稳定性:特别强调在视频重建中保持细节和时间稳定性。
- 跨模态视频VAE:结合文本和视频信息,提升视频编码的性能。
使用教程
1. 访问项目网页并下载代码。
2. 根据提供的文档安装必要的依赖和环境。
3. 运行代码,输入视频数据进行模型训练。
4. 利用训练好的模型对新的视频数据进行编码和重建。
5. 分析重建视频的质量,并根据需要调整模型参数。
6. 将模型部署到实际应用中,如视频编辑软件或视频分析系统。










