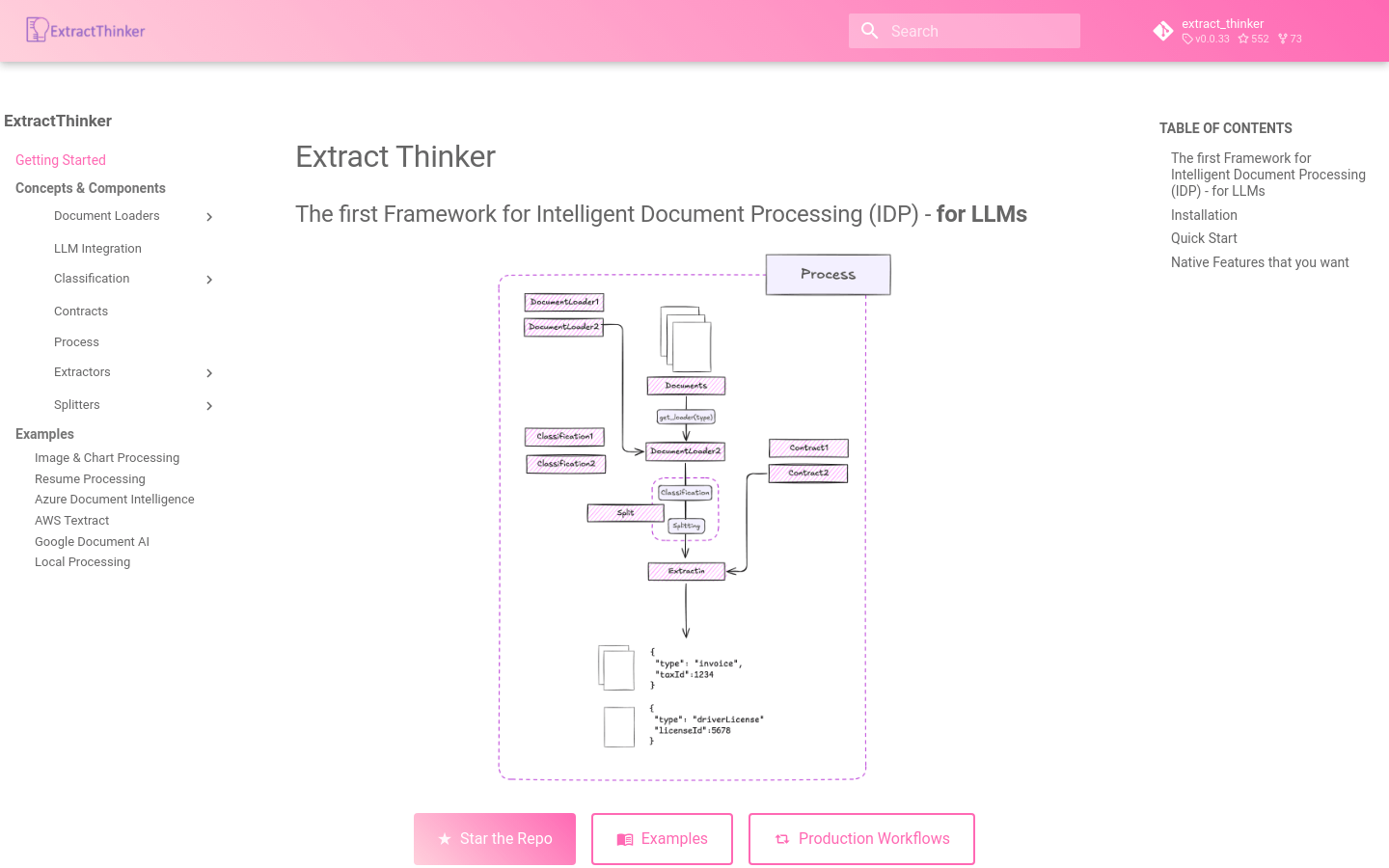
使用场景
从PDF中提取发票数据:使用ExtractThinker从PDF文件中提取发票编号、日期和总金额。
智能文档分类:对大量文档进行分类,识别不同类型的文档并进行相应的处理。
PII检测和处理:在处理敏感文档时,自动识别并处理个人身份信息,确保数据隐私。
产品特色
使用Pydantic进行数据提取:从任何文档类型中提取结构化数据,并使用Pydantic模型进行验证、自定义功能和提示工程能力。
智能文档分类和分割:支持共识策略、急切/惰性分割和置信度阈值的智能文档分类和分割。
PII检测:自动检测和处理文档中的敏感个人信息,采用隐私优先的方法和高级验证。
LLM和OCR中立:根据需求和成本要求,自由选择和切换不同的LLM提供商和OCR引擎。
使用教程
1. 安装ExtractThinker:使用pip安装extract_thinker。
2. 定义要提取的数据:创建一个继承自Contract的类,定义需要提取的数据字段。
3. 初始化提取器:创建Extractor实例,并加载文档加载器和LLM模型。
4. 从文档中提取数据:使用Extractor的extract方法从指定文档中提取数据,并传入Contract类。
5. 打印结果:打印提取的数据,如发票编号、日期和总金额。










