使用场景
在数学问题解答中,使用EurusPRM-Stage2模型来优化推理过程,提高解答的准确性和效率。
在逻辑推理任务中,利用模型的隐式过程奖励来提升推理的逻辑性和一致性。
在自然语言处理任务中,通过模型的强化学习优化来提高生成文本的质量和连贯性。
产品特色
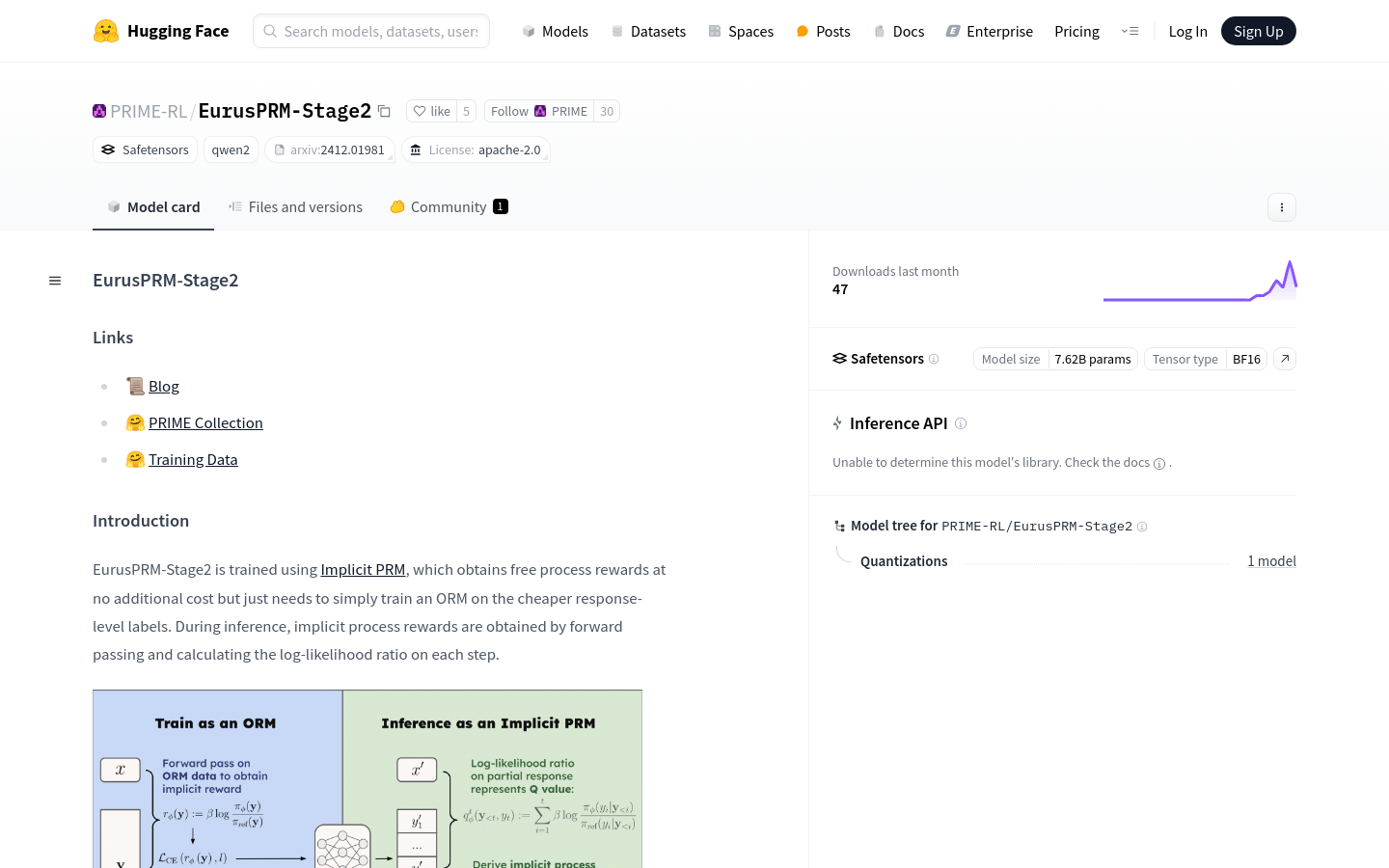
隐式过程奖励:通过计算对数似然比来获取过程奖励,无需额外标注。
强化学习优化:利用过程奖励来优化生成模型的推理过程。
多任务适应性:适用于多种需要复杂推理的任务,如数学问题解答。
高效训练:采用交叉熵损失进行训练,提高训练效率。
灵活的奖励表示:支持不同的训练目标和奖励表示方式。
数据高效:仅需响应级数据即可训练,减少数据标注成本。
强大的推理能力:在数学问题解答等任务中表现出色,提升生成模型的准确性。
使用教程
1. 加载模型和分词器:使用transformers库加载EurusPRM-Stage2模型和对应的分词器。
2. 准备输入数据:将问题和答案的文本转换为模型所需的输入格式。
3. 计算过程奖励:通过模型的前向传播计算每个步骤的对数似然比,从而获取过程奖励。
4. 优化推理过程:利用过程奖励来指导生成模型的推理过程,提高推理的准确性和可靠性。
5. 评估模型性能:使用合适的评估指标来评估模型在特定任务上的表现。










