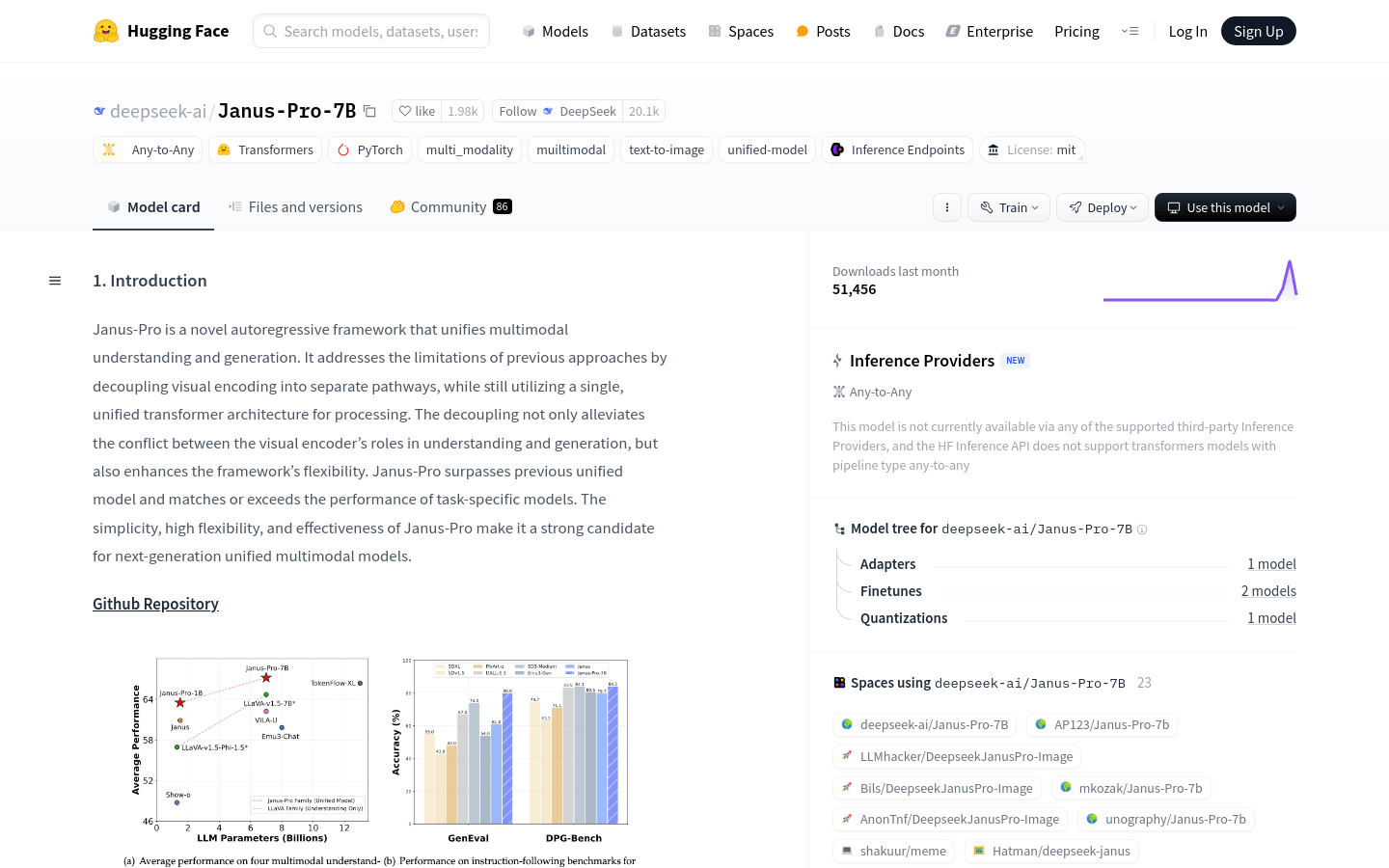
使用场景
图像生成:根据文本描述生成高质量图像
文本理解:分析图像内容并生成文本描述
多模态交互:结合文本和图像进行复杂任务处理
产品特色
支持多模态理解和生成,能够处理文本和图像数据
使用 SigLIP-L 视觉编码器,支持 384x384 的图像输入
基于 DeepSeek-LLM 架构,性能强大
模型设计灵活,适用于多种多模态任务
提供高效的多模态交互能力,适用于复杂场景
使用教程
1. 访问 Hugging Face 网站并找到 Janus-Pro-7B 模型页面
2. 下载模型文件或使用 Hugging Face 提供的 API 接口
3. 根据需要加载模型,输入文本或图像数据
4. 调用模型进行多模态任务处理,例如图像生成或文本理解
5. 分析模型输出结果,根据需要进行后续处理










