使用场景
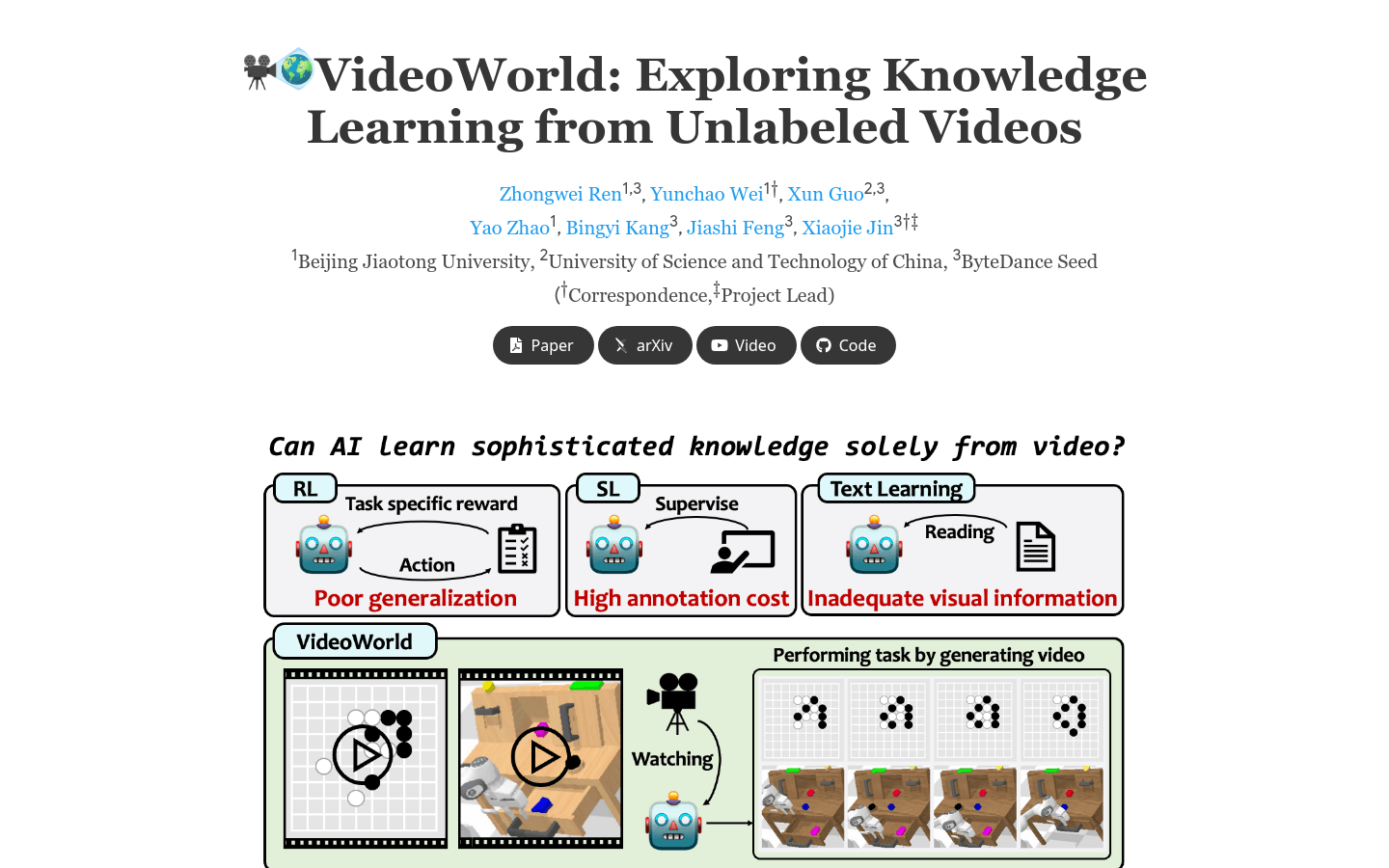
在视频围棋任务中,VideoWorld能够通过生成下一棋局状态来下棋。
在机器人控制任务中,VideoWorld能够控制机械臂完成多种操作。
通过潜在动态模型(LDM),VideoWorld能够高效学习和推理复杂的视觉任务。
产品特色
通过自回归视频生成模型学习任务规则和操作。
利用潜在动态模型(LDM)高效表示多步视觉变化。
在视频围棋任务中达到5段职业水平。
在机器人控制任务中实现跨环境泛化。
提供开源代码和数据,支持进一步研究。
使用教程
1. 访问项目主页,下载开源代码和数据。
2. 使用VQ-VAE将视频帧转换为离散token。
3. 训练自回归Transformer模型,采用下一帧预测范式。
4. 在测试阶段,模型根据前一帧生成新帧,并从中提取任务操作。
5. 应用潜在动态模型(LDM)以提升学习效率和性能。










