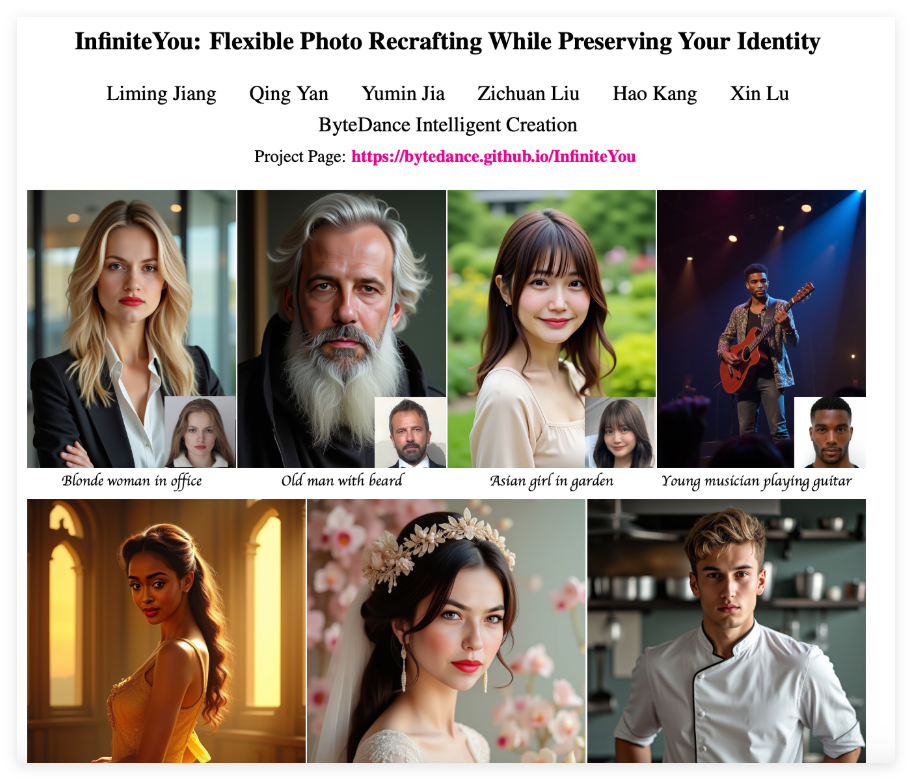
使用场景
用户通过提供文本提示生成个人化图像。
艺术家利用该模型创建独特的艺术作品。
研究人员在实验中生成数据以验证算法的有效性。
产品特色
采用残差连接注入身份特征,增强身份相似性。
多阶段训练策略,包括预训练和监督微调,提升文本 - 图像对齐。
兼容多种现有模型,支持自定义任务的灵活性。
提供易于使用的参数调整选项,以适应个性化需求。
具备较强的兼容性,支持与现有的控制网络和 LoRA 的结合使用。
使用教程
克隆 GitHub 代码库。
按照说明进行模型安装。
选择适合的模型变体(如 aes_stage2 或 sim_stage1)。
根据需要调整参数,例如 infusenet_conditioning_scale。
使用文本提示生成图像并进行评估。










