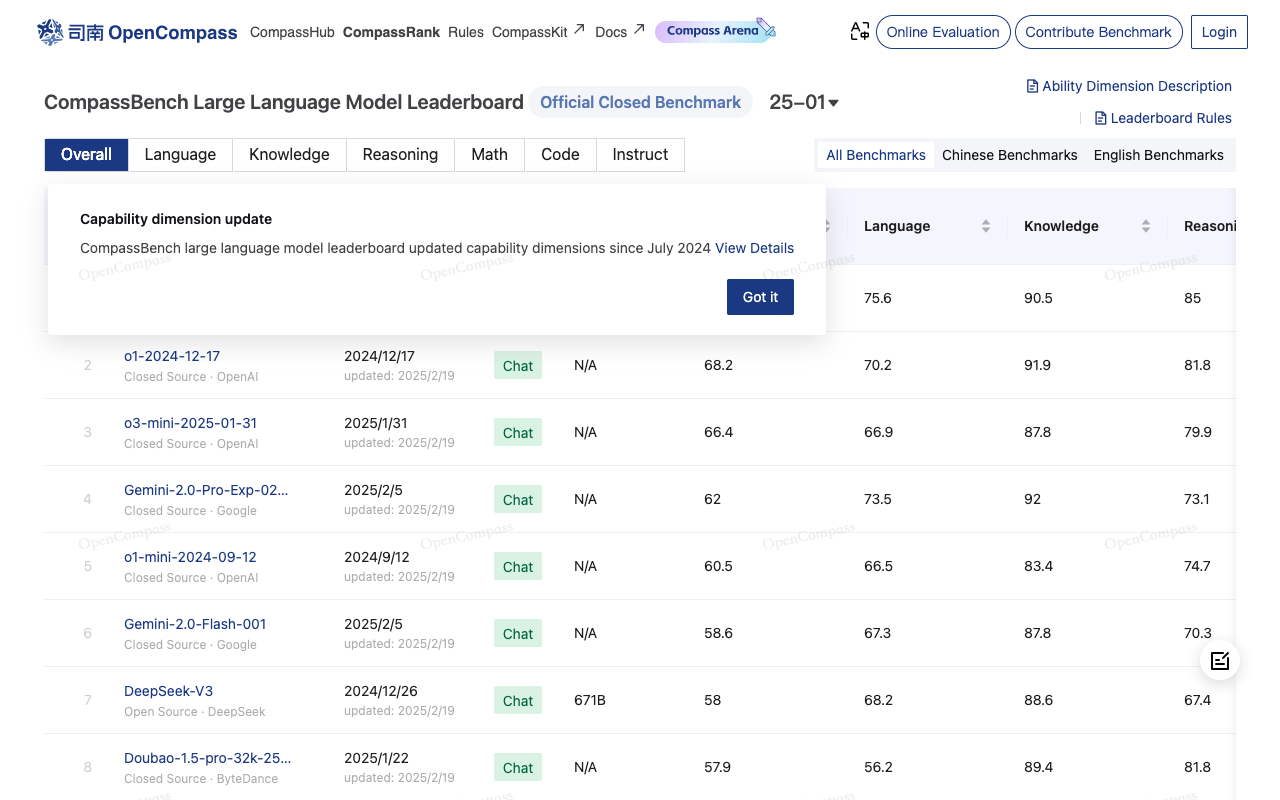
https://rank.opencompass.org.cn/leaderboard-llm 是 OpenCompass 平台的 LLM(大语言模型)排行榜页面,由 OpenCompass 社区维护。OpenCompass 是一个开源的大模型评估平台,旨在提供公平、开放、可复现的基准测试,用于评估大语言模型(LLM)和多模态模型的性能。该排行榜展示了众多模型在不同任务和数据集上的表现,是研究人员和开发者比较模型能力的重要参考工具。
网站功能与内容
-
模型性能排行
- 榜单展示了多种大语言模型的性能排名,包括开源模型(如 LLaMA、Qwen、InternLM)和商业 API 模型(如 GPT-4、Claude)。
- 排名基于模型在多个基准测试中的得分,综合评估其语言理解、知识储备、推理能力、数学计算、代码生成等维度。
-
评估数据集
- 排行榜使用超过 100 个数据集进行评估,涵盖:
- 知识推理:如 MMLU-Pro、GPQA Diamond。
- 逻辑推理:如 BBH。
- 数学推理:如 MATH-500、AIME。
- 代码生成:如 LiveCodeBench、HumanEval。
- 指令遵循:如 IFEval。
- 这些数据集的选择旨在全面衡量模型在不同场景下的能力。
- 排行榜使用超过 100 个数据集进行评估,涵盖:
-
透明与参与
- 用户可以通过提交模型的存储库 URL 或标准 API 接口参与评测(提交至 opencompass@pjlab.org.cn)。
- 平台提供详细的评估方法和结果,部分数据和配置可在 GitHub 上获取(如 https://github.com/open-compass/opencompass)。
-
动态更新
- 排行榜定期更新,反映最新模型的性能。例如,2024 年 9 月的更新显示,阿里云的 Qwen 2.5-72B-Instruct 成为首个登顶的开源模型,综合得分超越 Claude 3.5 和 GPT-4o。
-
可视化展示
- 网站以表格形式呈现排名,支持按综合得分或特定能力排序,便于用户直观对比模型表现。
使用场景
- 研究支持:研究人员可利用榜单数据分析模型优劣,推动算法改进。
- 模型选择:开发者可根据任务需求选择性能最佳的模型。
- 社区协作:鼓励用户贡献新模型或基准测试,丰富评估生态。
如何使用
- 访问 https://rank.opencompass.org.cn/leaderboard-llm 查看最新排名。
- 若想参与评测,可参考 OpenCompass 官网(https://opencompass.org.cn)或 GitHub 上的快速入门指南,提交模型进行测试。
意义
OpenCompass LLM 排行榜通过多维度、标准化的评估,为行业和研究社区提供了一个客观参考,推动了大语言模型的透明发展和性能优化。无论是想了解前沿模型表现,还是希望测试自研模型,这里都是一个权威且实用的平台。










