谷歌新研究:用 LLM 增强 LLM
AIGCBench:全面评估 AI 视频生成
PLLaMa:植物科学领域的开源大模型
清华团队新研究:大模型如何改变心理学研究?
Meta 新研究:在语音对话中合成 ” 人类 ”
Auffusion:一个新型文本到音频生成系统
LARP:开放世界游戏的语言代理角色扮演游戏
清华团队提出智能体 GitAgent,可基于 GitHub 自主扩展工具
DeepMind 提出 AutoRT:用大模型更好地训练机器人
AI 能像人类一样有创造力吗?
1. 谷歌新研究:用 LLM 增强 LLM
具有数十亿参数的基础模型,经过大量数据语料的训练,在多个领域表现出了不错的技能。然而,由于其单一庞大的结构,对其进行增强或传授新技能具有挑战性,而且成本高昂。另一方面,由于这些模型具有适应能力,目前正在针对新领域和新任务训练这些模型的若干新实例。
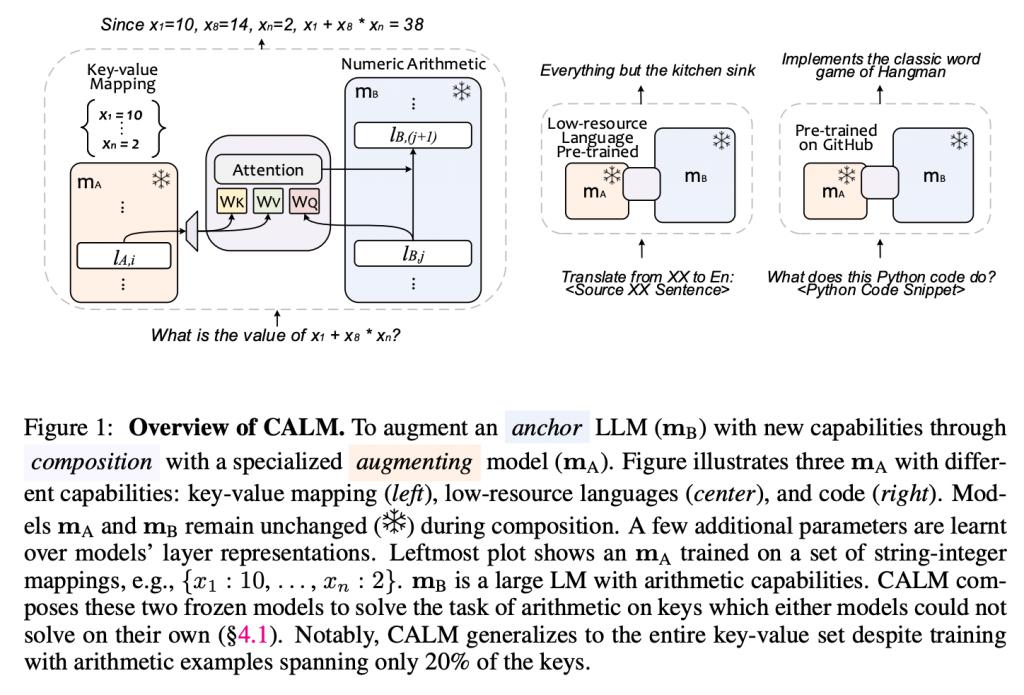
为此,来自 Google DeepMind 和 Google Research 的研究团队探讨了如何高效、实际地将现有基础模型与更具体的模型组合起来,从而实现新能力,并提出了 CALM,它通过模型间的交叉注意力机制来组合它们的表征。据介绍,CALM 的显著特点包括:
1)通过 ” 重新使用 ” 现有的大型语言模型(LLMs),以及少量额外的参数和数据,在新的任务中扩展 LLM;
2)保持现有模型权重不变,从而保留了现有的能力;
3)适用于不同的领域和环境。
研究结果表明,用一个在低资源语言上训练的较小模型增强 PaLM2-S,可以在诸如翻译成英语和低资源语言的算术推理等任务上,实现最高 13% 的绝对性能提升。同样地,当 PaLM2-S 与一个专门的代码模型结合时,在代码生成和解释任务上实现了 40% 的相对性能提升 —— 与完全微调的模型相当。