直接用成绩说话——
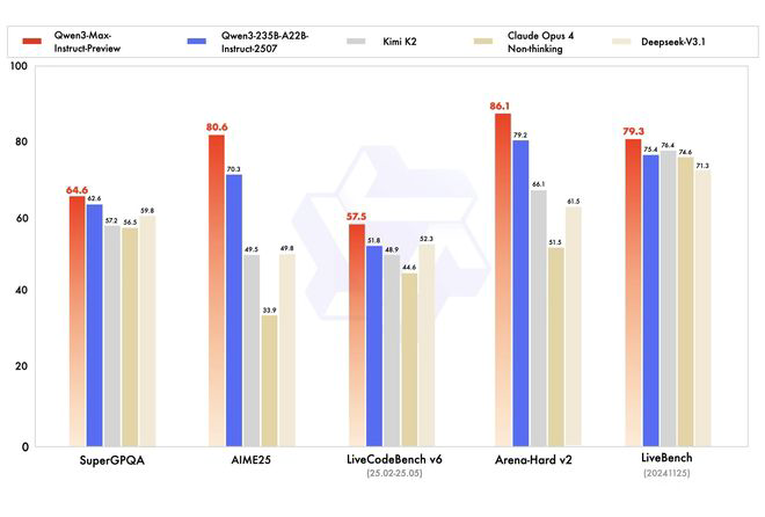
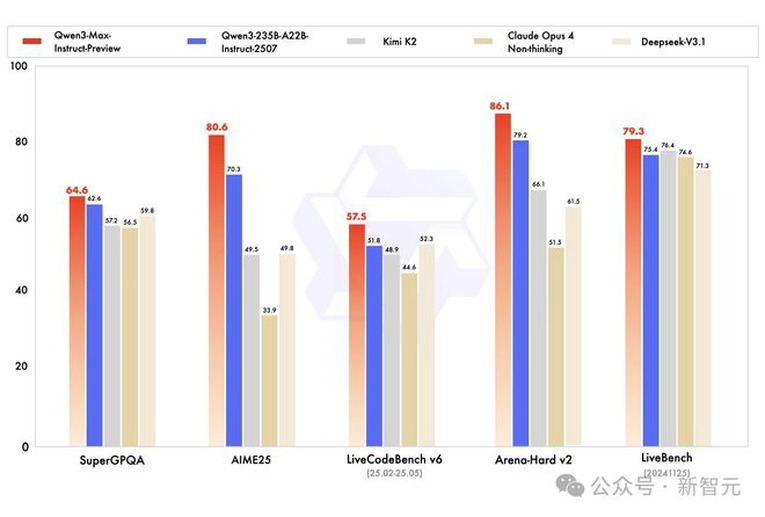
在全球主流权威基准测试中,Qwen3-Max-Preview狂揽非推理模型「C」位,直接碾压Claude-Opus 4(Non-Thinking)、Kimi-K2、DeepSeek-V3.1。
甚至,它把自家Qwen3-235B-A22B-Instruct-2507狂甩身后,堪称「AI卷王本王」。
· 知识推理评测(SuperGPQA)拿下64.6分
· 数学推理评测(AIME25)拿下80.6分,断崖式领先
· 竞争性编程评测(LiveCodeBench V6)拿下57.5分
· 复杂问题解决和人类偏好对齐评测(Arena-Hard v2)拿下86.1分,优势巨大
· 被称为「无法被操控的」评测(LiveBench)拿下79.3分
惊艳的性能表现再次证明了,Scaling仍然有效,参数越大模型性能越强。
总的来说,Qwen3-Max-Preview有以下几大亮点:性能更强、知识更广、更擅长对话、任务处理、指令遵循。
新模型可支持100+语言,还针对RAG、工具调用进行优化。
模型一出,全网立即开始了实测。
@karminski-牙医实测中,Qwen3-Max-Preview前端能力明显超越DeepSeek-V3.1。
比如,在一个杯子流体模拟中,Gemini 2.5在倾倒前杯子底部有严重bug,DeepSeek-V3.1杯子中物体倒出的状态(最后有一条线)不对,而Qwen3-Max-Preview比较符合物理常识。
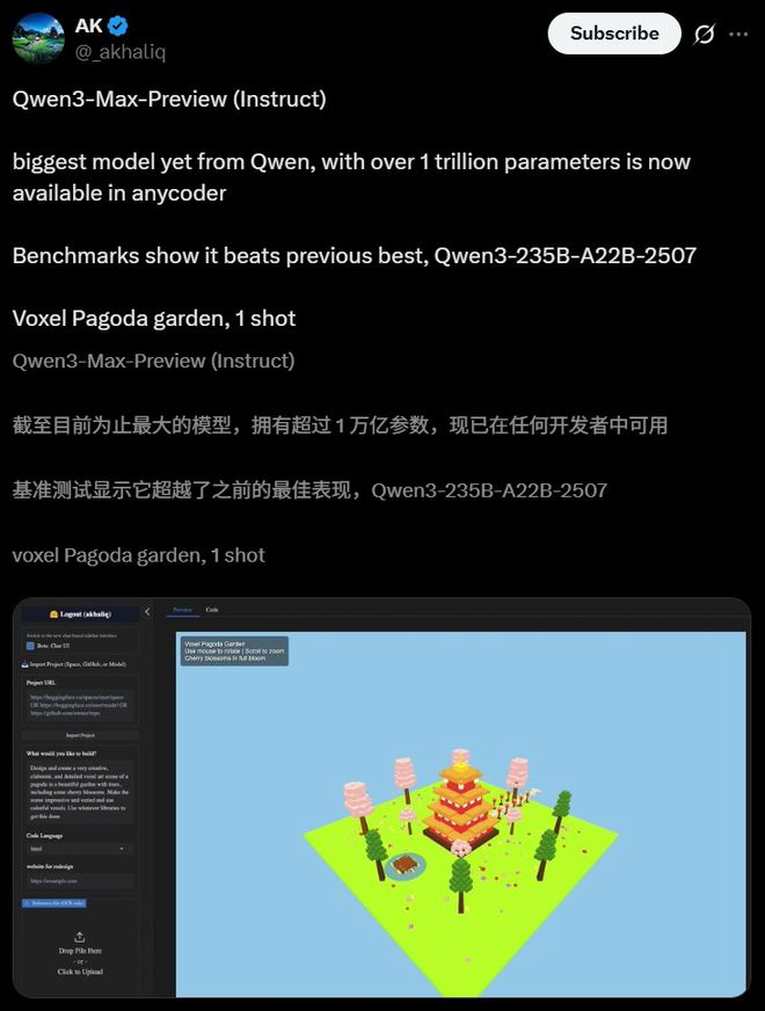
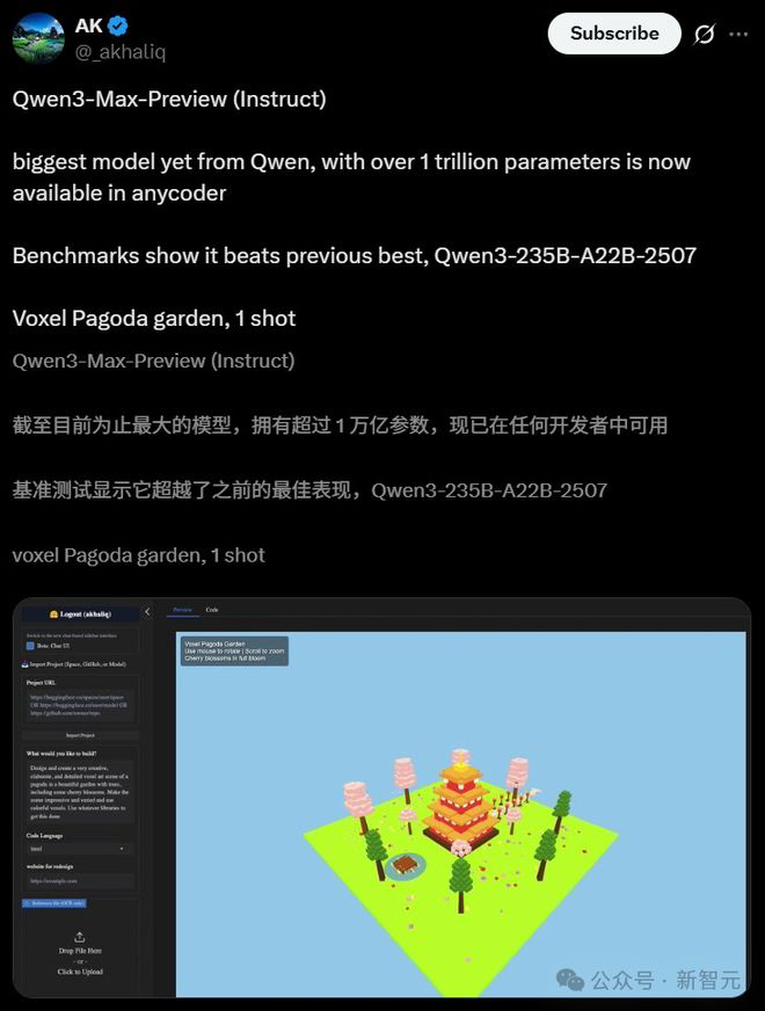
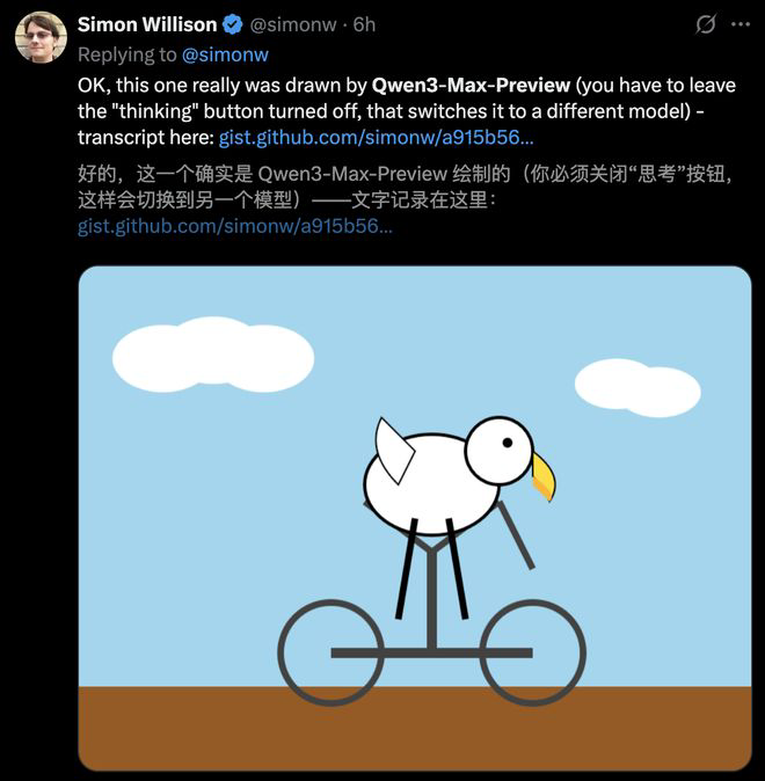
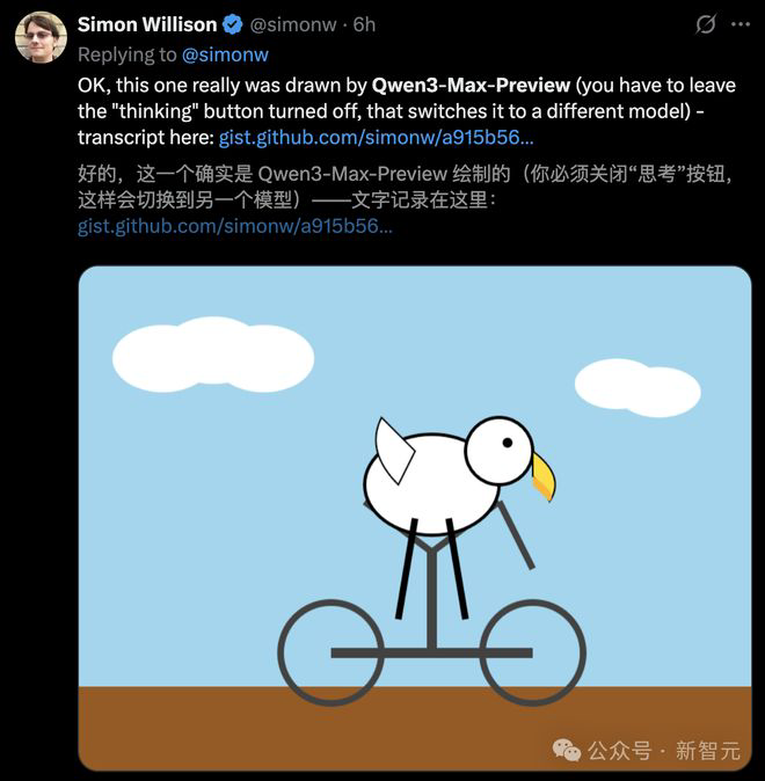
Qwen3-Max-Preview还能完美生成一个骑自行车的鹈鹕SVG、一键直出精美前端网页,一张照片做出像素花园。
目前,模型已正式上线阿里云百炼平台,可通过API直接调用。同时,Qwen Chat也同步上线新模型,支持免费使用。
在百炼平台上,最大支持256k上下文,依token数阶梯计费:
· 0-32k token:输入0.006元/千token;输出0.024元/千token
· 32k-128k token:输入0.01元/千token;输出0.04元/千token
· 128k-252k token:输入0.015元/千token;输出0.06元/千token