首页
资讯
经验
教程
应用
登录
搜 索
BERT
订阅
综合
图文
应用
资讯
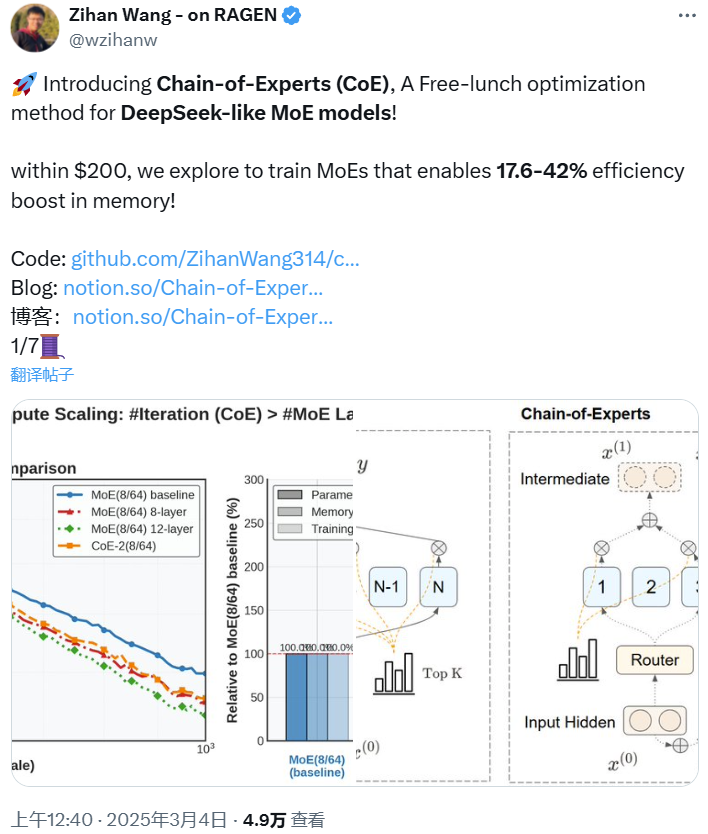
为DeepSeek MoE模型带来「免费午餐」加速,专家链可大幅提升LLM的信息处理能力
我们都知道,DeepSeek-R1 的训练过程使用了一种名为专家混合模型(Mixture-of-Experts, MoE)的技术,而当前的 MoE 技术依然还有...
AI,BERT,CLIP,emo,GPU,LLM,Meta,rl,token,Transformer,云计算,人工智能,代码,创新,北大,单张,参考文献,扩展语言模型,神经网络,论文,预训练,
08月18日
0
0
点击加载更多
猜你喜欢
人形机器人「朋友圈」的明牌和暗战
宇树科技专利侵权案一审判决:未构成侵权,原告败诉
OpenAI要刮油,谁会掉层皮?
用AI改造传统出行,这家公司推出万元级智能三轮车 | 涌现NewThings
刚刚,OpenAI Sora 2重磅登场!首个APP上线,或将成为AI时代新TikTok
字节信徒MiniMax