Adobe 最近宣布对其 Firefly AI 平台进行重大升级,这一变化使其从一个独立的图像生成器转变为一个综合性数字内容创作系统。自两年前推出以来,Fire...
AI,升级,视频,音频
07月30日
0
Stability AI最近又开源了一个模型,名字有点长,叫“Adversarial Post-Training 加速的快速文字转音频生成”,听起来很硬核对不对...
Stability AI,AI,开源,语音模型,音频
07月30日
0
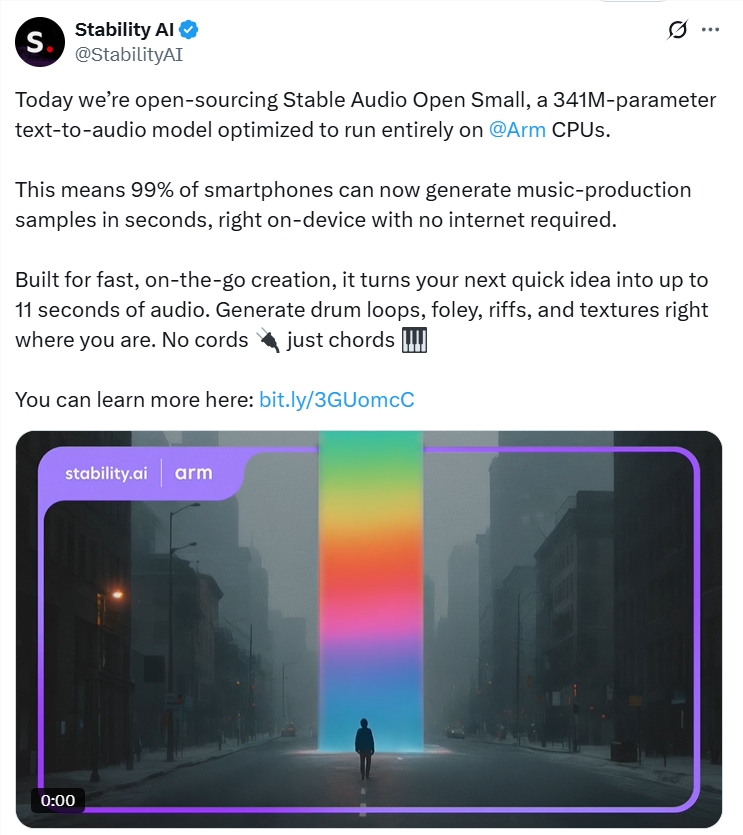
Stability AI和Arm联合发布了一款名为"稳定音频开放小型"(Stable Audio Open Small)的紧凑型文本转音频模型,该模型能够在约7...
Stability AI,AI,Arm,音频
07月30日
0
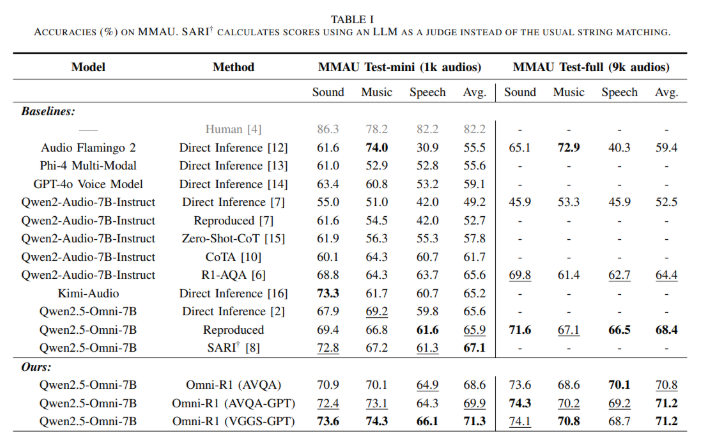
最近,一项来自 MIT CSAIL、哥廷根大学、IBM 研究所等机构的研究团队提出了一个名为 Omni-R1的全新音频问答模型。该模型在 Qwen2.5-Omn...
音频,问答,文本,强化学习,数据
07月30日
0
谷歌在I/O2025大会上正式揭晓Gemma3n,一款专为低资源设备设计的多模态AI模型,仅需2GB RAM即可在手机、平板和笔记本电脑上流畅运行。Gemma3...
谷歌,多模态,AI,音频,文本
07月30日
0
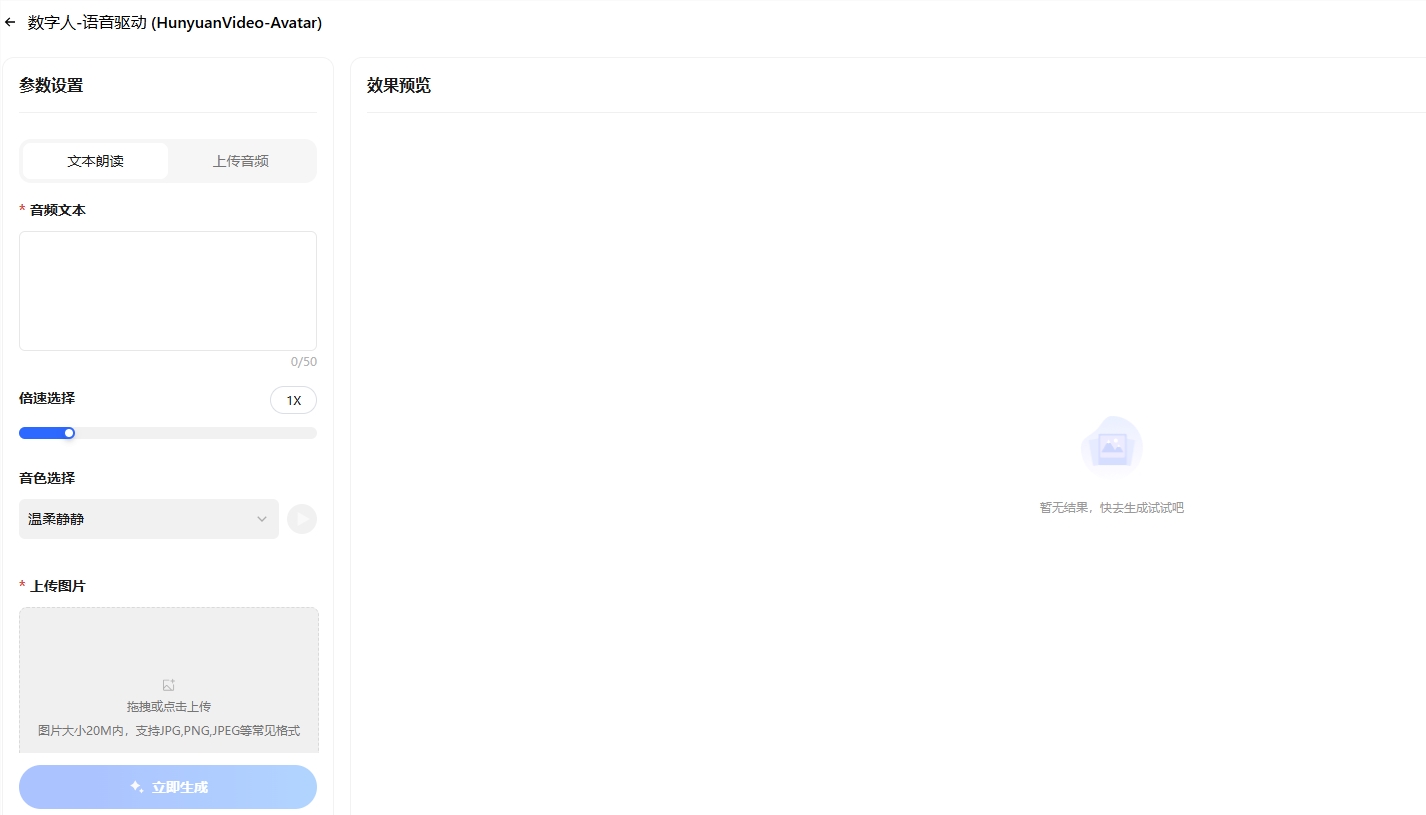
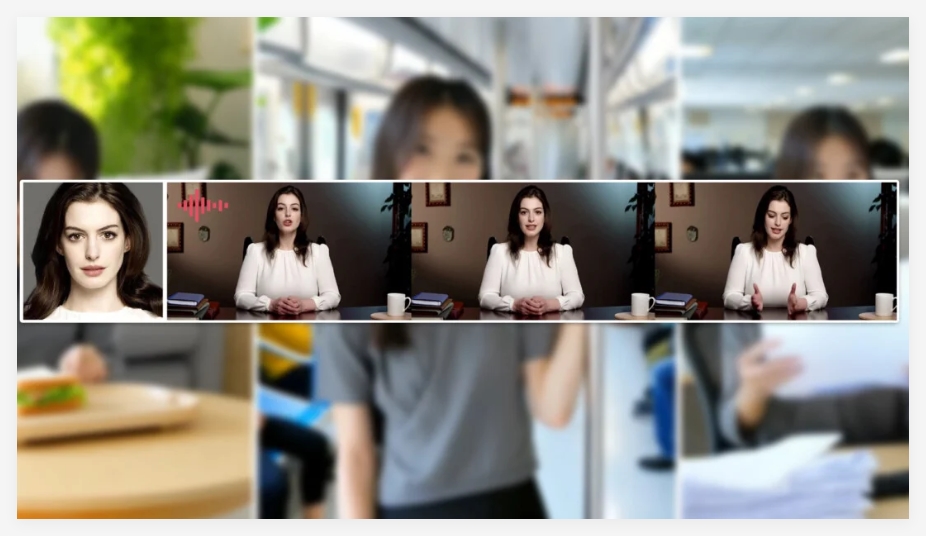
腾讯发布了一款创新技术 ——HunyuanVideo-Avatar 语音数字人模型,并将其开源。这一技术能够仅凭一张图片和一段音频,生成自然、真实的数字人说话或...
腾讯,混元,开源,音频,数字人
07月30日
0
近日,通义实验室语音团队在空间音频生成领域取得里程碑式成果,推出OmniAudio技术,该技术可直接从360°视频生成FOA(First-order Ambis...
通义,大模型,360,视频,音频
07月30日
0
2025 年 4 月 30 日 - AIbase报道:谷歌旗下AI研究助手NotebookLM迎来重大更新,其音频概述(Audio Overviews)功能现已...
Notebook,音频,多语言支持
07月31日
0
腾讯开源的一致性视频生成工具 “HunyuanCustom”,该模型不仅能生成生动的视频内容,还能实现音频与口型的同步。这一创新技术的发布,标志着在深度伪造视频...
音频,视频,腾讯,混元,开源,一致性
07月31日
0
近日, Vidu Q1系列 API 已正式面向全球开放。开发者与企业用户可借此契机,通过调用 API 体验 Vidu Q1模型所具备的多样化功能。此次开放的 V...
Vidu,API,上线,音频
07月31日
0